
、データは今日のビジネス環境において新たな石油とも称されます。しかし、多くの企業が直面する大きな課題の一つは、散在する様々なデータソースをいかにして統合し、有効に活用するかという点です。この記事では、まずデータ統合とは何か、そしてその重要性について解説します。
次に、データ統合を成功させるための目的や、初心者でも取り組める具体的な進め方を紹介していきます。データの世界に新たに足を踏み入れる方々にも、実践的な知識を提供します。
目次
1.データ統合とは
データ統合とは、異なる場所や形式で存在するデータを一つのシステムや形式にまとめることです。このプロセスは、企業が持つ様々な情報源からのデータを一つに集約し、一貫性のある分析や意思決定を可能にします。
例えば、あなたは大企業のマーケティング部門のマネージャーです。営業部のリーダーからはExcelファイルで顧客情報が、財務部からはPDFで販売データが、IT部からはデータベースのスクリーンショットでウェブサイトのトラフィック情報が提供されます。これらの情報は、形式も場所もバラバラです。
データ統合を行うことで、これらの異なるファイルと形式の情報を一つの統合されたシステム、例えば企業内の共有クラウドベースのプラットフォームに集めることができます。営業部からの顧客情報、財務部からの販売データ、IT部からのウェブトラフィック情報が全て同じフォーマットで、同じ場所にアクセス可能になります。
この統合プロセスは、パズルのピースを正しい位置に置くようなものです。各部門からのデータが一つの場所でつながることで、全体の絵が明確になり、より深い洞察が得られます。例えば、営業データとウェブトラフィックの関連性を分析して、どのオンラインキャンペーンが実際に売上に貢献しているかを把握することができます。
データマネジメントを推進するデータビズラボの研修資料をダウンロードする
2.データ統合を行うメリット
データ統合は、ビジネスにおいて重要な役割を果たします。以下は、データ統合の主なメリットです。
2-1.情報の一元化
一例として製造業での例を挙げましょう。製造業企業では、生産管理、販売、顧客サービス、財務管理といった各部門が別々のシステムを使用していることが多いです。例えば、
- 生産管理部門は、製造プロセスと在庫を管理するための専用ソフトウェアを使用。
- 販売部門は、別のCRMシステムで顧客情報と販売データを管理。
- 顧客サービス部門は、顧客の問い合わせやフィードバックを記録する独自のデータベースを持っていました。
- 財務部門は、経理と財務のデータを別の会計ソフトウェアで管理。
この状況では、部門間の情報共有が困難で、データの矛盾や重複が発生しやすく、全体像を把握するのが難しい状態でした。
そこで、企業はデータ統合の取り組みを開始し、これらの異なるシステムからの情報を一つの統合データベースにまとめました。これにより、各部門のデータがリアルタイムで一元的に閲覧できるようになり、次のようなメリットがもたらされました。
- 在庫管理の最適化:生産データと販売データがリンクされ、在庫レベルのより正確な管理が可能に。
- 顧客サービスの向上:顧客データと販売履歴が一元化され、顧客への対応が迅速かつパーソナライズされたものに。
- 財務分析の効率化:販売、生産、顧客サービスのデータが財務分析に容易に組み込まれ、より迅速な財務決定が可能に。
このように、情報の一元化は、部門間の壁を取り払い、効率的で一貫性のある意思決定を促進します。
2-2.統合前と統合後のイメージ
データ統合前の作業フロー
データ統合前は、データ取得までのプロセスが多く、すぐに分析を始めることができないことがほとんどです。具体的には以下のような煩雑な手順を行っている印象です。
- レポート作成者が、独立したシステム(データベース)から売上データをダウンロード
- レポート作成者が、データ管理者にデータ取得依頼メールを出す
- データ管理者が、最新データを取得し、レポート作成者へデータを送付する
- レポート作成者が、集めたデータを分析可能な形に加工する(Excelマクロ駆使)
- レポート作成者が、加工したデータを使ってレポートを作成する

データ統合後の作業フロー
データ統合後は、データ取得までの煩雑なプロセスがなくなり、分析にすぐ着手できます。具体的には以下のようなシンプルな手順になります。
- レポート作成者が、統合データベースから分析に必要なデータを探す
- レポート作成者が、1のデータを使ってレポートを作成する

2-3.データ統合による費用対効果は高い
実際にデータ統合をしたいと思っても、「コストがかかりそうで手をつけられない」と思われてる方もいらっしゃると思います。確かに実現までの人月コストは多くかかってしまうでしょう。しかし、統合したデータ基盤を上手に活用していけばROIは高まります。
仮に、データ分析者やレポート作成者のデータ収集・加工にかける工数を1人日とすると、毎月1回作業する人が20〜30人いるだけで1人月です。しかし、データを統合すれば、この1人月は削減できるため、データ統合基盤構築に6人月かかったとしても数ヶ月で元が取れるでしょう。
これが、大きな規模であればあるほどスケールしていき、全体としての生産性がどんどん高まっていくものです。
3.データ統合により生産性が向上した弊社のクライアント事例
3-1. 事例A: 小売業界の企業
事例Aの企業は、顧客データ、在庫管理、販売データが異なるシステムで管理されていました。データ統合により、これらの情報を一つのシステムで一元管理することが可能になりました。その結果、在庫の最適化、顧客へのパーソナライズされたマーケティングが可能になりました。
データアクセスの時間が大幅に削減され、経営意思決定の迅速化にも寄与しました。
3-2. 事例B: 製造業界の企業
事例Bの企業は、生産データと顧客フィードバックのデータを統合しました。この統合により、生産過程の改善点が明確になり、製品の品質向上に直接つながりました。
また、顧客満足度の向上にも貢献し、リピート率の増加が見られました。データ統合は、製品開発の効率化と市場適応の速度を高める重要な要素となりました。
4.データ統合の手順
データ統合は複雑なプロジェクトになることがありますが、以下の3つのステップに分けて進めることで、より管理しやすく効果的なプロセスを実現できます。

1. データの評価
データを統合するために行う一番最初のステップは、データを評価することです。データを評価することで、現状データの問題・課題を洗い出すことができます。
統合されたデータは全社員に使われる可能性があります。そのデータに間違いがあれば、全社員の示唆に誤りが生じます。そうならないためにもデータを適切に評価し、現状データの問題・課題(修正箇所)を徹底的に洗い出しておきましょう。
具体的には、以下2つの観点でデータを評価していきます。
これらの評価を行うことで、統合するデータの修正箇所が明確化できるからです。
- 構造の評価
- 内容の評価
以降、それぞれの評価について具体的に解説していきます。
構造の評価
社内のデータが、構造化されているデータか否かを評価していきます。最初にそれぞれのデータが構造化データなのか、非構造化データなのか確認します。
構造化データと非構造化データの違いは以下の通りです。

構造化データは、テーブル形式で整理されているデータです。注文日、製品などといったデータの項目(見出し行)が定義されているため、データの加工や、分析の切り口として活用しやすい形になっています。
非構造化データは、テーブル形式で整理されていないデータです。数字や文字で表すことのできないデータ(画像/動画)のため、データの加工や、分析の切り口としては活用しづらい形になっています。
また非構造化データには、Excel等で説明・報告しやすいように整えられたデータ(下記画像例)も含まれますが、この場合は構造化データに変換することが可能です。
上記画像では、表が折り返しを修正し表を縦に並べる等の処理を行う必要がある。
内容の評価
次にデータの内容を評価していきます。データの内容は、以下4つの観点で評価していきます。
- 想定しているデータ型で定義されているか
- 見出し行、データ行の関係性は適切か
- 複数データ間の粒度に違いがないか
- 複数データ間の表記に揺れがないか
これらを行う理由は、統合するデータ間の整合性を取るためです。統合されたデータ間の整合性が取れていないと、参照するデータによってインサイトに差異がでます。そうならないためにも、データの内容は入念に評価しましょう。
データ内容の評価方法(例)
実際にデータ内容を評価する4つのやり方を、例を用いて紹介します。今回の例で用いるデータは、以下の売上データ/関係者データです。
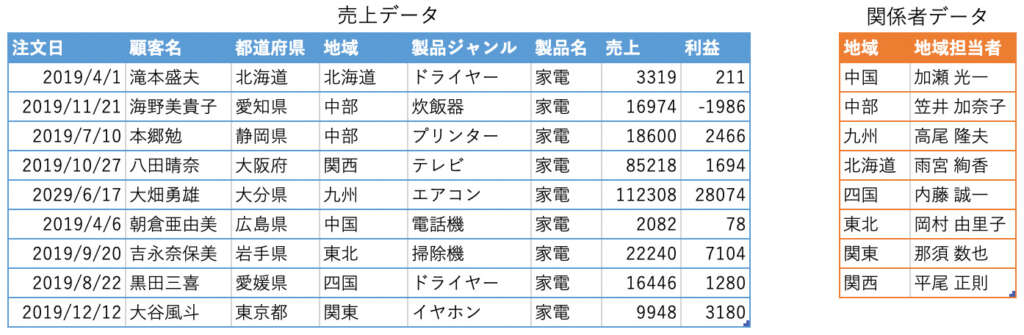
1. 想定したデータ型で定義されているか評価する

各データ列が、自身が想定しているデータ型(日付型データ、文字列型データ、数値型データ)で定義されているか評価します。以下は、想定しているデータ型で定義されています。

例えば、[利益]を数値型でなく文字列型にしてしまっていた場合は、「211 + 78 = 21178」という文字列の結合が行われてしまいます。このようなミスを起こさないためにも、自身の想定しているデータ型と差異がないか評価しましょう。
2. 見出し行、データ行の関係性は適切か評価する
各見出しの名称と、その見出しに紐づく実データの関係性が正しいかを評価していきます。以下は、製品名という見出し名称なのに、カテゴリ名の家電が入っている状態です。

実際、このようなことは、よくあります。隣の見出し名称と何かの拍子に逆になっていたから、などが主な理由です。このように、勘違いしたまま分析・レポート作成がされないよう、見出し行とデータ行の関係性は評価しましょう。

3. 複数データ間の粒度に違いがないか評価する
複数データ間で粒度の違いがないか評価します。同じ「地域」といっても、一つのデータには北海道、青森などの都道府県レベル、もう一方のデータには中国、中部、などの地域レベルのデータが入っていたりします。これは、データの粒度が違う状態です。
以下のデータは、「地域」データが同じ粒度で入っていることが確認できます。(※表記揺れについては後ほど触れます)

例えば以下は、一方は日ベースで、もう一方は月ベースの売上が入っている粒度が異なるデータです。このデータを一つにまとめてデータ分析を行ってしまうと、下期のデータだけ上期の数倍以上の値となって表示されます。このように、粒度が異なるデータで分析し、誤ったインサイトを得ないよう複数データ間の粒度は評価しましょう。
4. 複数データ間の表記に揺れがないか評価する
複数データ間で表記揺れがないかを評価します。表記揺れは、中部地方・中部という同じデータの意味を持つにも関わらず、違った表記がされていることを指します。以下の地域データは、まさに表記揺れがある状態です。このような表記揺れがあると、異なるデータとして扱われるため集計結果に影響が出ます。そのため、データ間に表記揺れがないか評価しましょう。



以上がデータ内容の評価例です。
2. データの整形
1で行った「データの評価」に合わせて、最適な整形をするステップです。これらの整形を行うことで、データの品質/精度が高まり、統合する準備が整います。以下の手順で行います。
- 誤ったデータの補正・・・見出し名称や入力のミスを修正します。
- 不要なデータの削除・・・データ量を減らすために使用しないデータを削除します。
- 粒度の統一・・・・・・・複数テーブル間で、データの粒度を統一します。統合を行う際には粒度の粗いデータに統一します。(月毎と日毎のデータがあれば、月毎に統一)
- 表記の統一・・・・・・・複数テーブル間で、一致していない名称や表現を統一します
データの整形の注意点
このステップで注意すべき事項として、「整形するために行った処理を後から確認できる」状態とすることです。
値を整形する作業自体に誤りがある場合に、元のデータはどのようになっていて、どの処理が原因なのかしっかりと確認できる形で進める必要があります。
そのため整形を行う際には、SQLやTableau Prep、Informatica PowerCenter、Talend Data Integration、Power Query(Excelのデータ加工機能)等のツールの活用が推奨されます。
3. データの集約
いよいよ最後のステップです。Excel、データベース、クラウドなど様々な場所に散在するデータを一箇所に集約していきます。
集約にあたり重要となるポイントが2点あります。
- 適切なプラットフォームの選定
- 集約データの辞書化
以降説明していきます。
適切なプラットフォームの選定
集約先のプラットフォーム選定を行いましょう。統合するデータを評価し、いくら品質を上げても、集める場所がなければデータを統合できません。そのため、どこにデータを集約していくかを決めます。
代表的なプラットフォームとしては以下があります。
・GCP(Google Cloud Platform)
・AWS(Amazon Web Service)
・Microsoft Azure
しかし、これら代表的なプラットフォームを挙げられても、何が良くて、どう選んで良いか分からない方が多いと思います。そのような方に向け、データプラットフォームの基礎知識から、導入時のアドバイスまでがまとまっているこちらの記事をご紹介させていただきます。
https://data-viz-lab.com/data-platform
プラットフォームが決まった後は、散在しているデータを、以下のように集約していきます。集約(インポート)のやり方は、プラットフォームの仕様に合わせて行ってください。

集約データの辞書化
集約したデータは辞書化(一般的にデータカタログと呼ばれる)しましょう。データを統合しても、参照したいデータが何処にあるのか分からなければ、すぐに分析に着手することができません。
- データカタログ機能はプラットフォームのサービスの一部として提供される場合が多いため、選定したプラットフォームのデータカタログ機能を有効に活用しましょう。
- データカタログを構成する要素は統合したデータのメタデータになります。メタデータとは実データの付帯情報のことで、具体的には以下のようなものを指します。
- データの名称 (家電売上)
- データの説明 (何年度の家電製品売上データです)
- データ形式 (Excel)
- データを作成した組織 (営業部門)
- データ作成者 (佐藤 太郎)
- データ作成者の連絡先 (xxx-xxxx-xxxx)
- データ作成日 (xxxx年xx月xx日)
売上データにこれらのメタデータが付帯されていれば、売上データを参照したい誰かが "売上" や "家電売上" 等と検索するだけで、上記データがヒットし、簡単に参照することができます。そのため、統合後の運用も考えて、統合するデータにはメタデータを付与しておきましょう。
5.データ統合にまつわるよくある質問と回答
5-1.データ統合を進めるためにおすすめのツールはなんですか?
データ統合のためのツール選択は、組織のニーズに大きく依存します。以下は、市場で広く使用されているいくつかの主要なデータ統合ツールとその特徴です。
Informatica PowerCenter
強力で柔軟性の高いエンタープライズ級のデータ統合ソリューションで、大規模なデータセットと複雑なデータ統合プロセスに適しています。
Talend Data Integration
オープンソースでコスト効率の良いデータ統合ツールで、シンプルなインターフェースと幅広いデータソースへの対応が特徴です。
5-2.データ統合は誰が指揮を取って進めるべきですか?
データ統合プロジェクトの成功は、適切なリーダーシップに大きく依存します。いずれにしても、指揮者には、データマネジメントに関する専門知識、プロジェクト管理能力、コミュニケーションと協調性が必要になります。
多くの組織では、これらの資質を持つITマネージャー、データマネージャー、またはシニアアナリストが、データ統合プロジェクトのリーダーとして選ばれることが一般的です。プロジェクトの規模や組織の構造に応じて、適切なリーダーを選出することが重要です。
5-3.データ統合は支援会社の協力を得るべきですか?
データ統合プロジェクトにおいて外部の支援会社を利用するかどうかは、専門知識の有無、リソースの制約、保有する技術レベルによって異なりますが、多くの場合、社内リソースだけで行うのは日常業務に支障が出過ぎるもしくはプロジェクト遂行まで時間がかかりすぎるという点で現実的ではありません。
プロジェクトの目的と要件に基づいて、最適な決定を行うことが重要です。
6.データ統合を進めすならデータビズラボとの伴走がおすすめ
これからデータ統合を進めようとされているなら、当社データビズラボとの伴走がおすすめです。
6-1.専門知識と実績
データ統合の専門家としての豊富な経験と成功事例を保有しています。これにより、様々な業界やビジネスニーズに合わせたカスタムソリューションを提供することが可能です。
6-2.データ統合プロジェクト遂行に必要となる広範囲なデータ経験
データ統合にはデータの上流から下流まで、広範囲なデータの経験が必要です。当社では、データ分析、ビジュアライゼーションに至るまで、データに関わるあらゆるニーズに対応して参りました。これにより、一貫したサービスを通じてデータの価値を最大限に引き出すことができます。
6-3.最新技術の活用
AI、機械学習、ビッグデータ技術など、最先端のテクノロジーを駆使してデータ統合の効率化と精度向上を図ります。
6-4.専門知識と実績
データの専門家としての豊富な経験と成功事例を保有しています。これにより、様々な業界やビジネスニーズに合わせたカスタムソリューションを提供することが可能です。
以下は、データ分析・可視化について公開できる実績の一例です。実績一覧はこちらをご覧ください。この他にもお伝えできる事例は多数ございますので、お気軽にお問い合わせください。
 |  |  |
株式会社ユーザベース様 | ”データを見る文化”醸成を目指し、分析可視化・社内カスタマーサクセスチームの立ち上げ等実施 | 優れた予測アルゴリズムの価値をデータ可視化で具現化。 |
 |
|
|
|
|
|
UI/UXデザイナー向けに、データの可視化スキル向上にフォーカスした育成向上プログラムの支援を実施 | ||
|
|
|
|
|
|
|  |
|













7.まとめ
今現在も、あなたの企業のデータは増え続けています。しかし、色々なシステムが乱立(サイロ化)していては、溜まっていくデータを有効活用できません。
今回はその現状を打破するためのデータ統合のやり方を3つのステップでお伝えしました。
DX(デジタルトランスフォーメーション)の第一歩もデータ分析環境の整備から始まります。是非、この手順をご活用いただいてデータ統合基盤を構築し、自社に眠るまだ価値を発揮できていないデータの価値を高めてください。
データのことなら、高い技術力とビジネス理解を融合させる私たちにご相談ください。
当社では、データ分析/視覚化/データ基盤コンサルティング・PoC支援に加え、ビジュアルアナリティクス、ダッシュボードレビュー研修、役員・管理職向け研修などのトレーニングを提供しています。組織に根付くデータ活用戦略立案の伴走をしています。




