



売上予測は事業計画において予算の分配や資金調達、出店計画の立案などのベースとなる重要な指標です。企業は以下のニーズから、ツールを導入したりデータ分析のスペシャリストを採用したりして予測の精度向上を目指しています。
- 設備投資額がいくらまでなら採算が見合うのか知りたい
- 株主や投資家に事業の見通しについて説明しなくてはならない
- 黒字を維持しつつ拡大する出店計画を立てたい
- 新発売の商品の売れ行きを予測し、製造量の見込みを立てたい
本記事では、その中でも特に店舗開発に焦点を絞り、以下のポイントについて解説します。
- 失敗する原因
- 売上予測の精度を上げるために必要なこと
本記事をお読みいただくことで新規出店の際に正しく売上予測を行うことができるようになり、長期的な視点で経営判断をすることができるようになります。
目次
1.店舗開発における売上予測とは
多くの企業が立地条件や商圏の広さ、客層から売上予測を立て、設備投資や賃料などのコストと比較し、採算が見込めるかどうか考えて出店計画を立てています。しかし大抵の場合、予測は百発百中とはいかず、思うように売り上げが上がらないまま赤字に陥る店舗が出てきます。

1.1 店舗開発における売上予測とは
店舗開発においても店舗と商品カテゴリ両方の観点から売り上げを予測することができます。新規出店する際には基本的に立地条件しかデータが与えられていないため、
- 店舗あたりの売上予測
- 目的:フランチャイズオーナーへの説明資料、出店戦略の立案
- 手段:数値的な精度がとても重要。立地条件や商圏規模、マーケットボリュームなどサードパーティーデータと現在所有している店舗のPOSデータなどのデータを合わせて分析・予測を行う。
- 商品あたりの売上予測
- 目的:在庫管理、設備投資の見通し
- 手段:売上予測をベースにどれくらいの在庫を持つべきかを計画できる。店舗の立地条件や、広さによってどの商品カテゴリを優先的にストックしておくか判断することで欠品による機会損失や在庫過多による廃棄量を減らすことができる。
売上予測が正確でないと、リソースの配分が適切にできなくなり大量の在庫を抱えたり先行投資に見合ったリターンが得られず赤字に陥ってしまったりと重大な問題が発生します。正確な売上予測をするためには予測に必要なデータと最適な分析手法を選択する必要があります。
1.2 売上予測がうまくいかない理由
売上予測がうまくいかず、精度が低くなってしまう理由は主に以下の3つです。本章ではこれらの要因について具体的に解説いたします。
- 必要十分なデータ量がそろっていない
- 売上予測のロジックに根拠の薄い変数が入っている
- 担当者に十分なデータの知見がない
必要十分なデータ量がそろっていない
予測モデルの構築には大量のデータが必要です。仮に既存店舗が100件あり、それぞれ開店から10年ほど年数が経っていれば、合計で1000件の売上データがあることになります。
加えて、それら1件1件のデータに加えて以下の売上に関連性がある変数も紐づいている必要があります。
- 出店時の商圏人口
- 通行量(歩道/車)
- 商圏人口の性別
- 昼間人口/夜間人口の比率
- 店舗の面積
- 店舗の視認性
- 競合店舗の距離と数
以上のような変数から予測モデルを構築し、精度を検証しながらモデルのアップグレードを行います。
データが十分にそろっていない典型例としては以下があります。
- 出店当時は通行量の測定などをしていたものの、出店後は調査していない
- 過去のデータの計測条件と今調査しているときの計測条件が異なる
- 店舗ごとに集計方法が異なる
売上予測のロジックに根拠の薄い変数が入っている
根拠の薄い変数とは、例えばキャッチ率や回転率といった値です。それぞれ日によって大きく変動する上に、推定するのが困難なのでこれらを用いた売上予測は希望的な値になってしまい、精度が低くなります。ただ、回転率を計算する際の店舗面積や席数、キャッチ率を計算する際の通行量などは売り上げを考える上で大事な要素になります。また、キャッチ率や回転率以外にも、商圏人口で商圏として想定している範囲は果たして妥当なのか、など注意するべき指標は多くあります。
- 回転率法
この方法は、客席数、客単価、1日の回転数(何回満席になるかを表す数値)、営業日数を用いて売り上げを予測するものです。以下の式から売上予測を計算します。
- キャッチ率法
キャッチ率とは、「店の前を通る人のうちの何%が来店するか」という数値です。通行量、キャッチ率、客単価、営業日数といった指標を使い、以下の式から売上予測を計算します。

担当者に十分なデータの知見がない
売上予測を担当している調査部や経営戦略部などのメンバーに、十分なデータ分析の知見や立地への知識がないと単に「それらしい値」を作る作業になってしまいます。
例えばデータ分析の基本的な作法として、予測をテストするためのテストデータとモデルを作るための学習データは分けなくてはいけません。それだけでなく、データの特性や分布に応じて精度検証の手法自体を変えたり、モデルが過学習の状態になっていないかを見たりする必要があります。
このように正確な売上予測には人材育成コストからデータ分析を行う基盤の構築など、多くのコストと時間がかかります。データ分析のスペシャリストに依頼することで、人材育成にかかるコストを減らし精度向上までにかかる時間を節約することができます。
データビズラボでは、お客様のご状況にあわせてプロフェッショナルがさまざまな観点で精緻にレビュー・把握し、必要なデータや最適なアプローチを複数パターンでご提示します。
1.3 精度の高い売上予測を実現する3つのステップ
精度の高い売上予測を行い、迅速な意思決定をするためには調査➡分析➡可視化という3つのステップが必要です。それぞれで具体的にどのようなことをするのか簡単にまとめました。
STEP1:調査
- 保有しているデータを確認
- 既存の予測モデルを確認
- デスクトップリサーチ(公開情報の集約)
- 行政データを用いたマーケットリサーチ(以下使用データ例)
- 総務省:総合統計データ(人口・世帯、住宅・土地、地域など)
- 経済産業省:産業分析レポート
- 厚生労働省:人口移動、世帯変動に関するデータ
- 国土交通省:地価公示、都道府県地価調査データ
- 各都道府県地図情報(用途地域、人口総数、人口密度、人口密度増減率、世帯総数、人口増減率など)
STEP2:分析
- 複数のデータソースを分析基盤の構築によって一元化
- データの結合
- データプラットフォームの構築
- 行政データや既存のデータを用いた高度な立地分析
- 商圏とターゲット層から今後10年の市場規模予測(例)
- 予測(例)
- その他外部データによるデータ分析
STEP3:可視化
- 探索的分析と可視化
- 先行投資をいつまでに回収できるのかをシミュレーション
- 売上予測とSNSでの反応やリピート顧客の割合などをダッシュボードで見える化
- 万一売上が想定より伸び悩んだ場合の撤退するべきタイミングをシミュレーション
精度の高い売上予測を実現するため、当社ではご状況に合わせて調査から分析、戦略的判断に至るまで一気通貫でご支援いたします。また、御社で自律的に予測モデルを運用できるようデータ分析基盤の構築からリアルタイムの可視化までを実装いたします。
無料お役立ち資料配布中
データビジュアライゼーションの「見えないところ」まで理解が深まる
「データ視覚化/ダッシュボードデザインを成功させる95のチェックリスト」

2.精度を高める分析手法の導入
十分なデータ量があり、分析できる人材がそろっている場合は重回帰分析を用いることで高精度の予測をすることができます。一方で、データがあまりない場合にオススメな市場シェア率法や比較法についても詳しく解説し、各手法を導入するまでのステップや注意するべきポイントについてご紹介しています。
2.1 市場シェア率法
市場シェア率法で予測を立てるために必要なデータは以下の2つです。市場シェア率は、「市場(商圏)全体に対して何%のシェアを占有できるか」という数値です。
- 市場規模
- 周辺店の魅力を測る変数
商圏の広さを正しく設定できるか、シェア率の根拠をはっきりと持つことができるかが重要です。近隣の競合店舗をリサーチするだけで予測を立てられるというメリットもありますが、もし十分にデータが用意できる場合にはこの後でご紹介する重回帰分析の方が精度という観点からはオススメです。
市場シェア率法では、以下のステップで売上予測を算出します。
- 市場規模の算出
- 周辺店の魅力度を算出
- 出店候補物件の魅力度を算出
- シェア率を算出
- 売上予測を計算
大型の家具店を出店する場合を想定して、実際に計算してみましょう。
Step1:市場規模を算出する
国が実施している「家計調査年報」から、1世帯あたりの家具に対する支出を調査します。2020年の場合、家具・家事用品に対する1世帯あたりの支出金額は、121,911円です。
次に、出店候補地の商圏内にある世帯数を調べます。商圏範囲をどう設定するかは、周辺の地理環境や都市部かどうか、駐車場や店舗自体の広さによっても変わってきます。ここでは、商圏を車で10分圏内に設定し、その中の世帯数が2,000であるとします。
その場合、年間の市場規模は
121,911円 × 2,000 = 約2億4千万円と算出できます。
Step2:周辺店の魅力度を算出
自店とシェアを取り合うであろう周辺店(競合店)をピックアップ、各店の「魅力度」を算出します。
Step3:出店候補物件の魅力度を算出する
下表のように、お客様がお店を選ぶ基準となりそうな項目を挙げて点数をつけ、合計しましょう。出店候補物件の魅力度をStep2で算出した他店舗と同様の基準で算出します。
Step4:シェア率を算出する
出店候補物件の魅力度を、Step2で算出した競合店全店と出店候補物件の魅力度の合計で割ることで、シェア率を算出します。今回の場合、魅力度の合計が180なので、以下の式より、21.1%と計算できます。
シェア率 = 38 ÷ 180 × 100 = 21.1%
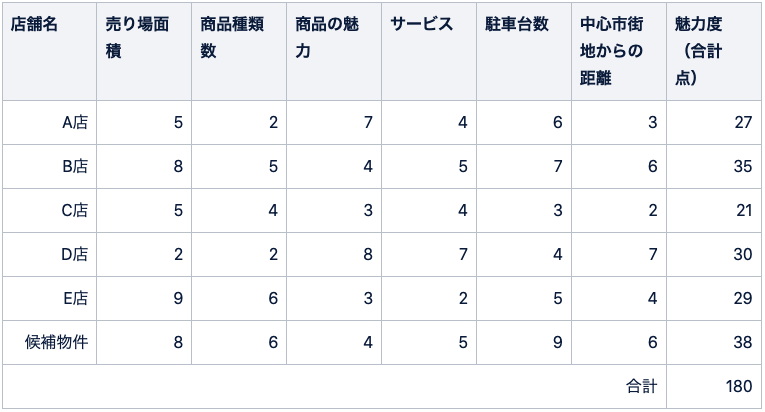
最後に、Step1の市場規模にStep4の市場シェア率をかけた値が、売上予測(年商)です。今回の例では、約5,100万円と計算できます。
売上予測(年商)= 市場規模 × シェア率
売上予測(年商) = 約2億4千万円 × 0.211 = 約5,100万円
2.2 比較法
比較法は「立地条件や出店形態の類似した店舗と比較することで予測する」ものです。重回帰分析と比べると精度は劣りますが、十分なデータ量が確保できないときには有効な手法だと言えます。
以下のステップで売上予測を求めます。
- 比較のための既存店選定
- 立地要因の設定
- 点数付けと比較表作成
- 評価項目の比重設定
- 売上と立地総合店の相関分析
- 評価項目の比重調整
- 売上予測の式を構築
- 候補店の売上予測を計算
Step1:比較に使う既存店を選定
既存店から比較に使う店舗を選択します。既存店が5〜10店舗の場合は全ての店舗を評価して下さい。
10店舗を超える場合は、候補地と類似した条件の店舗を10店舗ほど選びます。路面店が候補であれば、路面店を10店舗程度、テナントが候補であれば、テナントを10店舗程度選ぶといったイメージです。今回は、以下に示す売上の店舗を選択した場合を想定します。
今回は店舗A~店舗Eを比較に使う既存店に設定します。
Step2:評価項目にする立地要因を選定
既存店に点数をつけて比較するため、点数をつける評価項目を設定します。評価項目としては、以下4つのカテゴリに属する立地要因を網羅するよう設定しましょう。
- 商圏:人口・世帯数(商圏規模)や性別や年齢層(商圏の質)など
- お客様からのアクセス:視認性や人々の動線上にあるかなど
- 物件:面積や間口幅、駐車場面積など
- 競合:周辺の競合店舗の影響
Step3:既存店それぞれに評価項目の点数をつけ、比較表を作成する
Step2で決めた評価項目に基づき、既存店それぞれに点数をつけていきます。この際、人によってブレが発生しないよう、点数の付け方の基準を明確にしましょう。具体的には、以下のようなイメージです。
このように設定した基準に基づいて既存店に点数をつけ、以下に示すような「比較表」を作成します。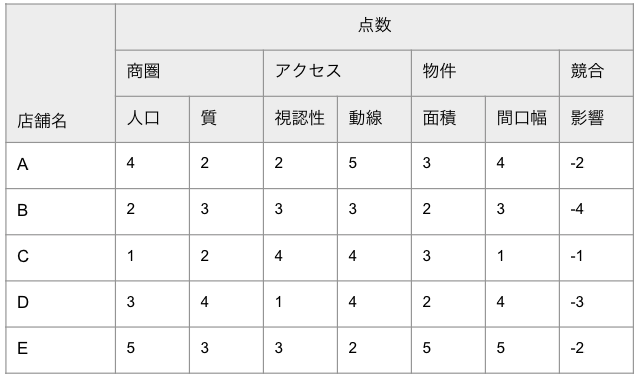
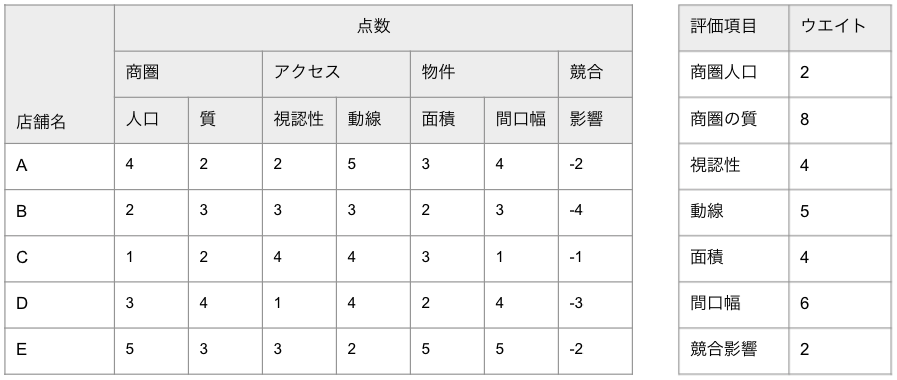
Step4:評価項目それぞれに、点数にかけるウエイトを設定する
Step3で評価した項目それぞれに、ウエイトを設定していきます。後で調整するため、この段階ではなんとなく「この項目は影響が大きそうだな」と思われるものに大きい値を、そうではないものに小さい値を設定する程度で問題ありません。
ただし、ウエイトの大きさ自体に大きな差があると計算が複雑になってくるので、1から10の間の値を設定しましょう。今回の例では、以下のように設定します。
Step5:売上と立地総合点の相関を分析する
評価項目それぞれにウエイトを掛け算した値を合計して立地総合点を算出します。この値を用いて売上と立地総合点の相関を分析していきます。具体的には、売上と立地総合点の相関係数を計算し、評価します。
相関係数は2種類のデータ間の関連性を示す指標です。そのため、相関係数を求めることで「立地が良ければ売上も良い」ということを客観的な数値で示すことができます。相関係数については、以下の記事で詳しく解説しています。
今回のケースで計算した結果、以下のようになりました。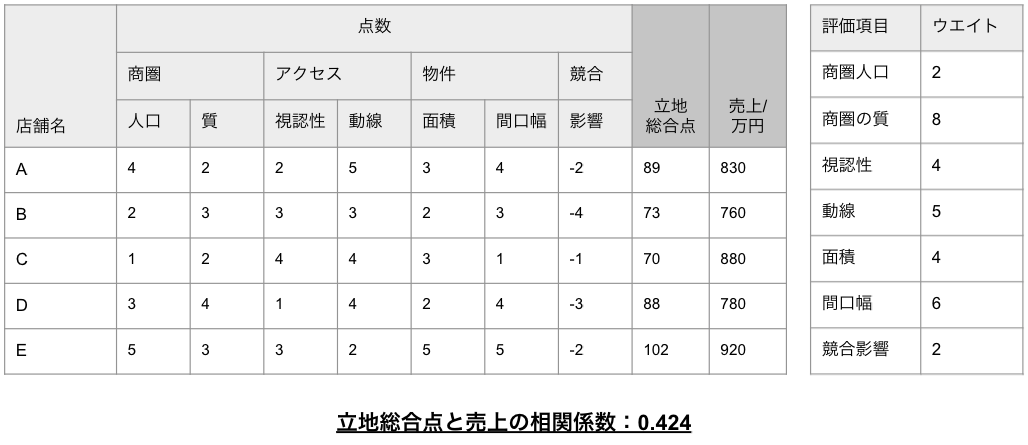
相関係数は、-1〜1の間の値となり、1に近いほど正の相関が強い、すなわち立地が良ければ売上が良いということを示します。一般的に、0.7を超える値となった場合に「正の相関が強い」と言われるので、今回の場合は相関があまり強くないことがわかります。
Step6:評価項目それぞれにかけるウエイトを調整する
Step5の計算で、立地総合点と売上の相関があまり強くないという結果が得られました。これでは「立地が良ければ売上が良い」という前提と一致しません。これをウエイトを見直し、それぞれの立地要因が売上に及ぼす影響を再調整することで解消します。
例えば、最初はウエイトを2に設定していた評価項目のウエイトを5に変更することで相関係数が大きくなれば、実際はその項目が売上に強く影響しているということです。
逆にウエイトを小さくした場合に相関係数が大きくなる項目があれば、その評価項目の影響は小さいということになります。このようにしてウエイトを調整し、相関係数が大きくなる条件を見つけていきましょう。
相関係数の値が最低でも0.7、可能であれば0.9以上となるように調整しましょう。今回のケースでは、以下のように調整することができました。
今回の場合、当初の想定よりも商圏の質の影響が小さく、視認性や面積、競合の影響が大きいことがわかりました。
Step7:売上予測を計算する式を作成する
売上予測を立地総合点から予測するため、以下のような一次式を作成します。

この一次式のaとbに入る具体的な数字を回帰分析という方法で求めます。以下の記事で回帰分析に関して詳しく解説しています。
今回の場合は、以下のような式が得られました。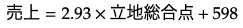
Step8:式を使って候補店舗の売上を予測する
ここまで出来たら、Step3と同様にして候補店舗の評価を行い、算出した立地総合点を式に代入することで売上予測を計算できます。
例えば、候補店舗の立地総合点が80点であれば、売上予測は約832万円となります。
この手法の注意点として、立地総合点と売上の相関係数が低いままだと精度の高い売上予測が立てられないことがあげられます。加えて、ウェイトを見直して相関係数にこだわりすぎるとモデルに偏りが生じ、第1章でご紹介した過学習に近い状況になってしまいます。
2.3 重回帰分析
重回帰分析は十分なデータ量がある場合に有効な手法で、比較法をさらに発展させてより精緻な予測を可能にします。比較法では評価項目にウエイトをかけて合計した「立地総合点」から予測式を作成しました。重回帰分析では、任意のn個の立地要因についてそれぞれ係数を算出し、以下のような式を作成します。

以下のステップで分析していきます。
- 分析に使う既存店舗の選定
- 売上に最も強く影響する立地要因「主変数」の選定
- 主変数を使った回帰分析で売り上げの理論値を算出
- 理論値と実際の売上との差を分析
- 誤差の要因を整理し予測
- テストデータで検証
- 実際の予測に運用
Step1:分析に使う既存店舗の選定
まず、分析に使う既存店舗を決めます。その際に重要なのは、徒歩来店型・車来店型・商業施設内型の3つの立地タイプ別に分け、一つのタイプの中から30〜50店舗選ぶことです。
- 徒歩来店型:徒歩での通行人がメイン客層
- 車来店型:車で来店する人がメイン客層
- 商業施設内型:ショッピングモールなどの商業施設内にテナントとして出店するタイプ
ここで2つ注意して頂きたいのが「異なる立地タイプをまとめて分析することはできないこと」と「ランダムにサンプルを選ぶこと」という事です。
例えば車来店型の店舗と徒歩来店型の店舗では雨によって受ける影響が異なります。徒歩来店型の店舗は徒歩で移動する必要があるので雨がマイナスに作用する可能性が高いです。
一方、車来店型の店舗の売上はそれほど変わりません。移動が車なので来客に対して雨がマイナスに作用しないためです。また、ランダムにサンプルを選ばないと分析に使われる店舗の共通点が立地要因と売上の相関関係を歪めてしまいます。
重回帰分析を行う際には立地タイプ別に店舗を振り分け、出店候補と同じタイプの既存店舗からランダムに分析用店舗を決めましょう。
Step2:売上に最も強く影響する立地要因「主変数」の選定
分析の第一段階では、売上に最も強く影響する立地要因を決定します。これを「主変数」と呼びます。売上に影響すると思われる要因を洗い出し、売上との相関係数を算出して最も相関係数が大きい要因を「主変数」としましょう。
主変数として設定して良いのは、個人の主観が入らない定量的な数値です。例えば周辺500m圏内の人口や、駅からの距離、店舗面積などです。視認性といった個人の主観が入るものに設定してしまうと、分析者によってブレが大きく、再現性のない予測式になってしまいます。
本来は30店舗以上の既存店舗データを使うのが理想ですが、簡易的に10店舗の模擬データで予測します。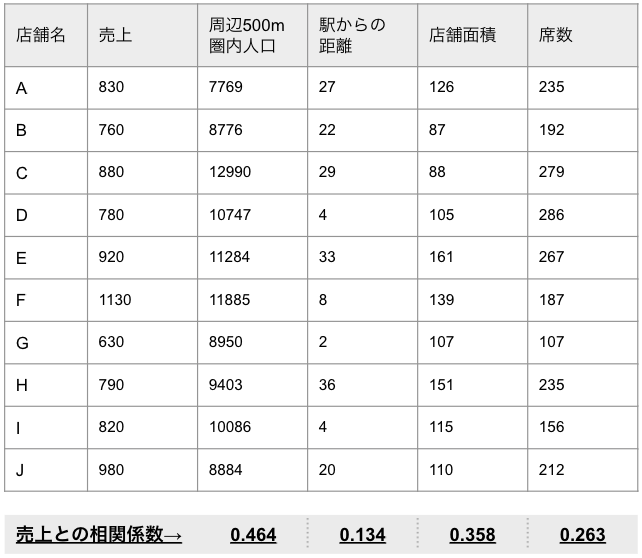
この場合、周辺500m圏内人口に最大の相関係数が見られるので、これを主変数に設定します。
Step3:主変数を使った回帰分析で売上の理論値を算出
続いて、主変数のみを用いた回帰分析を行い、作成した式から既存店舗の売上の理論値を求めます。比較法でも紹介していますが、回帰分析のやり方をこちらの記事で丁寧に解説しています。
今回の想定では、回帰分析により以下の式が求められます。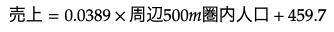
この式から売上の理論値を店舗ごとに求めた結果を、以下の表に示します。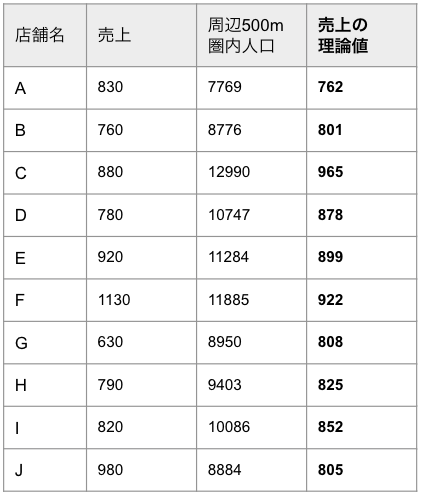
Step4:理論値と実際の売上との差「残差」を分析
Step3で算出した理論値と実際の売上とのズレを確認するため、理論値と実際の売上との差である「残差」を分析します。残差を求めた結果、プラスに大きなズレがある店舗は、売上に貢献する要因が主変数以外にあるとわかります。一方、理論値がマイナスに大きくズレている店舗は、売上を下げている要因があるというわけです。この点を把握できれば、理論値と実際の売上との差が大きい店舗を細かく見ていくことで、主変数以外の売上に影響する要因を探ることが可能です。今回のケースで残差を求めると、以下のような結果が得られました。この結果から、店舗FやJにおいては売上へ良い影響を及ぼす要因が主変数の他にあり、店舗Gにおいては売上への悪影響となる要因があると考えられます。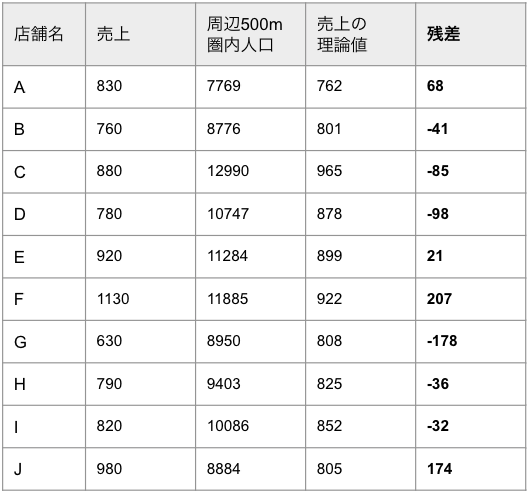
Step5:残差が大きい要因を整理し、予測式を作成
Step4で確認した残差が大きい店舗を調査し、売上に好影響な要因と悪影響な要因をそれぞれ予測します。次いで売上に影響すると予測した要因を数値化し、それを主変数に加えて重回帰分析を実施します。重回帰分析はExcelでも可能です。やり方に関しては以下の記事で詳しく解説しています。
要因を変数として加えて重回帰分析を行い、残差を分析するという作業を繰り返すことで、実際の売上と理論値との差を小さくしていきます。その際、重回帰分析で作成した予測式と実際の値との一致度合を示す「自由度調整済み決定係数」(Excelで重回帰分析を行った場合、補正R2で出力されます)と呼ばれる値が、0.8以上になる事を目指しましょう。
例えば、以下のようなイメージで理論値の実際の売上に対する一致度を高めていきます。
- プラスに大きい残差の店舗を調査すると、メニューの種類数が他店よりも多かった
- メニューの種類数を変数として加え、重回帰分析を行った
- まだ残差が大きい店舗があったので、その店舗を調査すると、視認性が他店より優れていた
- 視認性を数値化した上で変数として加え、重回帰分析を行った
今回のケースでは、以下のように変数を加え、予測式を立てることができたとします。
Step6:分析に使わなかった既存店舗で予測式を検証
予測式を立てることができたら、分析に使わなかった既存店舗のデータを使って検証しましょう。
分析に使わなかった既存店舗における予測式に関わる数値をまとめ、理論値を計算してみます。これで、実際の売上と理論値との差が小さければ、精密な予測式を立てることができたといえるでしょう。一方、50%以上もの大きなズレが生じてしまった場合は、分析をやり直す必要があります。
Step7:予測式を使って候補店舗の売上を予測
Step6の検証の結果、予測式に大きなズレがないことが確認できれば、売上予測を計算します。方法は単純で、候補店舗における予測式に関わる数値をまとめ、式に当てはめて計算するだけです。
今回想定のケースで候補店舗の評価が以下の表のようになった場合、Step5で作成した売上予測式より、売上予測を972万円と算出することができます。
- 変数が多すぎると分析の精度が下がってしまうため、分析に用いる要因は多くても7つまで
- 要因間に強い関連性があるとき、この手法では正確な予測ができない(多重共線性)
- 多重共線性の問題を防ぐため、重回帰分析をする前に予め変数間の関連の強さを確認し、相関係数が高い変数の一方を取り除く必要がある
まとめ
本記事では売り上げ予測のための分析手法をいくつか紹介しました。以下にポイントをまとめます。
- 各分析手法に必要なデータは何かを確認する
- 収集するデータはできる限り正確性の高いものにする
- 店舗規模や目的に応じた分析手法を用いる
正確なデータに基づいた精度の高い売り上げ予測を行い、経営に活かしていきましょう。
データビズラボでは、正確なデータを基にし、最大限に経営に活かすご支援をさせていただいております。
状況やニーズに合わせた様々なサポートをご提供いたしますのでぜひお問い合わせください。
また、質の高い売り上げ予測を行うためには、データの可視化も有効な手段です。以下の記事でその一例をご紹介していますので、是非ご一読ください。
無料お役立ち資料配布中
データビジュアライゼーションの「見えないところ」まで理解が深まる
「データ視覚化/ダッシュボードデザインを成功させる95のチェックリスト」


コメント