
独学でデータ分析をPythonで始めてみたいけれど、情報が散在しているせいで、どこから手をつけるべきかわかりにくいですよね。私もそうでした。
ド文系かつ独学で勉強をしてきた私は、今となっては実務でシミュレーションなどまでできるようになったものの、最初は結構手こずりました。「あ、これって始める前に知っておけばよかった・・・!誰か最初に教えてくれよ・・・!」というポイントが振り返るとたくさんあります。本記事ではこのような私の経験を踏まえ、Pythonを使ったデータ分析の仕方を効率的に学習するためのロードマップをご紹介いたします。
これを知っておけば、私のように無駄な時間をかけることなくPythonでの学習をスムーズに行えるはずです!
また、データ分析そのものについては以下の記事をご参照くだ。
データ分析とは?目的や重要性などデータ分析の基礎知識を解説
目次
6つステップで自走できるようになる
以下の6つのステップを踏むことで、最終的に自分の力でデータ分析を行えるようになります。
- ステップ1:学習すべき3要素を知る
- ステップ2:環境構築をする
- ステップ3:Pythonの基本を覚える
- ステップ4:主要なライブラリをマスターする
- ステップ5:データ分析の一連の流れを把握し、写経する
- ステップ6:自分で一から分析する
各ステップは、それ以前のステップで習得した要素を必要とします。そのためステップは飛ばさずに理解していく必要があります。学習を進めていく中で前のステップを再度理解し直す場合もありますが、一度学習をしたステップの内容ならば2度目はすんなりと理解できるはずです。
以下、各ステップにおける内容をコツや注意点も含めてみていきます。
ステップ1:学習すべき3要素を知る
「環境構築」、「Python言語の習得」、「分析作業の理解」が、Pythonでデータ分析を始めるために必要な3要素です。
Pythonの文法ばかりを勉強しているだけでは、データ分析を行えません。分析を行うためには、Pythonに関する言語的な知識のほかに、Pythonをコーディングし実行する環境と、分析に関する一連の流れを知る必要があります。
これは料理を行うときと同じように考えられます。料理を行うには料理を行う場所としてキッチン等の調理場が必要です。次に食材を調理する道具として包丁やボウルなどの調理器具の使い方を覚えなければなりません。そして最後に、作りたい料理のレシピを得ることで、初めて料理を作ることができます。
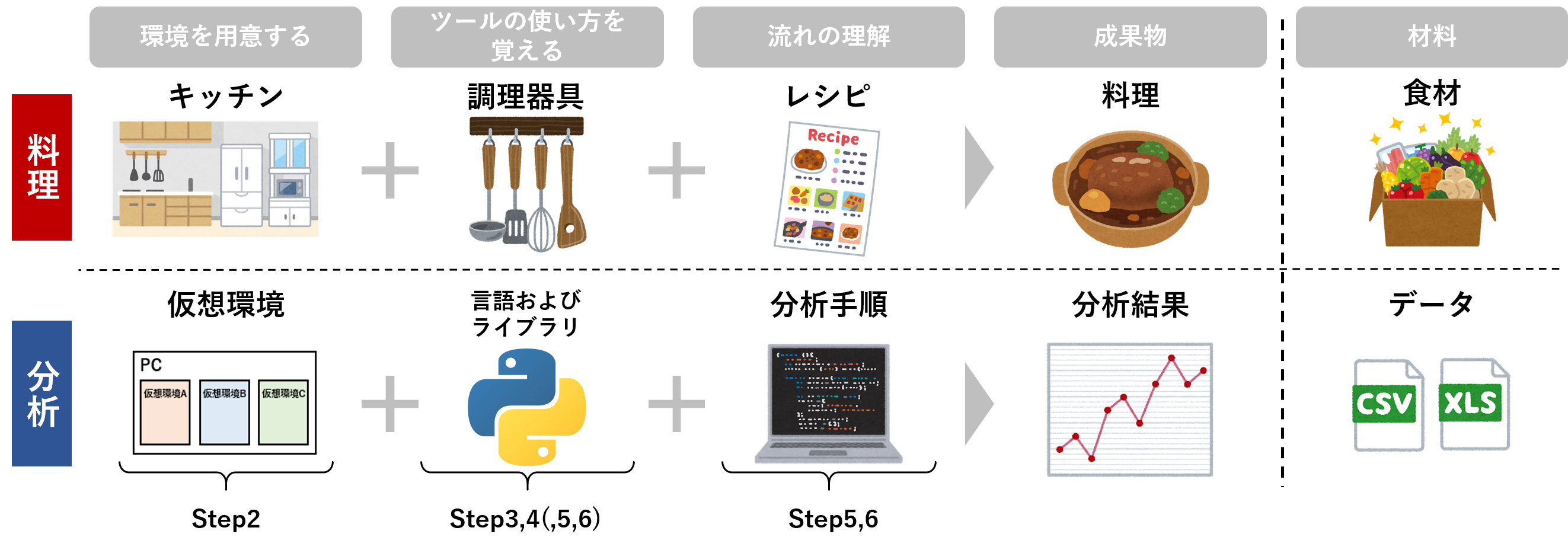
Pythonを使ったデータ分析でも、➀コードを書く環境を用意し、②コードの書き方を覚え、➂分析の流れを設計することでようやく、分析に臨むことができます。
したがって以下の残りの5ステップは、この3要素を習得してくためのステップだといえます。
ステップ2:環境構築をする
「環境構築」、「Python言語の習得」、「分析作業の理解」の3要素のうち、Pythonを動かすための「環境」を用意できなければ、Pythonの学習すらできません。そしてこの環境構築は初学者最大の難関かと思われます。最初私もやり方が全く理解できず、多くの時間を浪費しました。しかし以下4つを事前に頭に入れておくことで、初学者でも環境構築に迷わなくなります。
➀分析は「仮想環境」の中で行われる
自分のPC上でPythonを使用してデータ分析を行うとき、仮想環境と呼ばれるものを作成する必要があります。仮想環境とは、パソコンの中に複数の仮のパソコンが入っているイメージです。
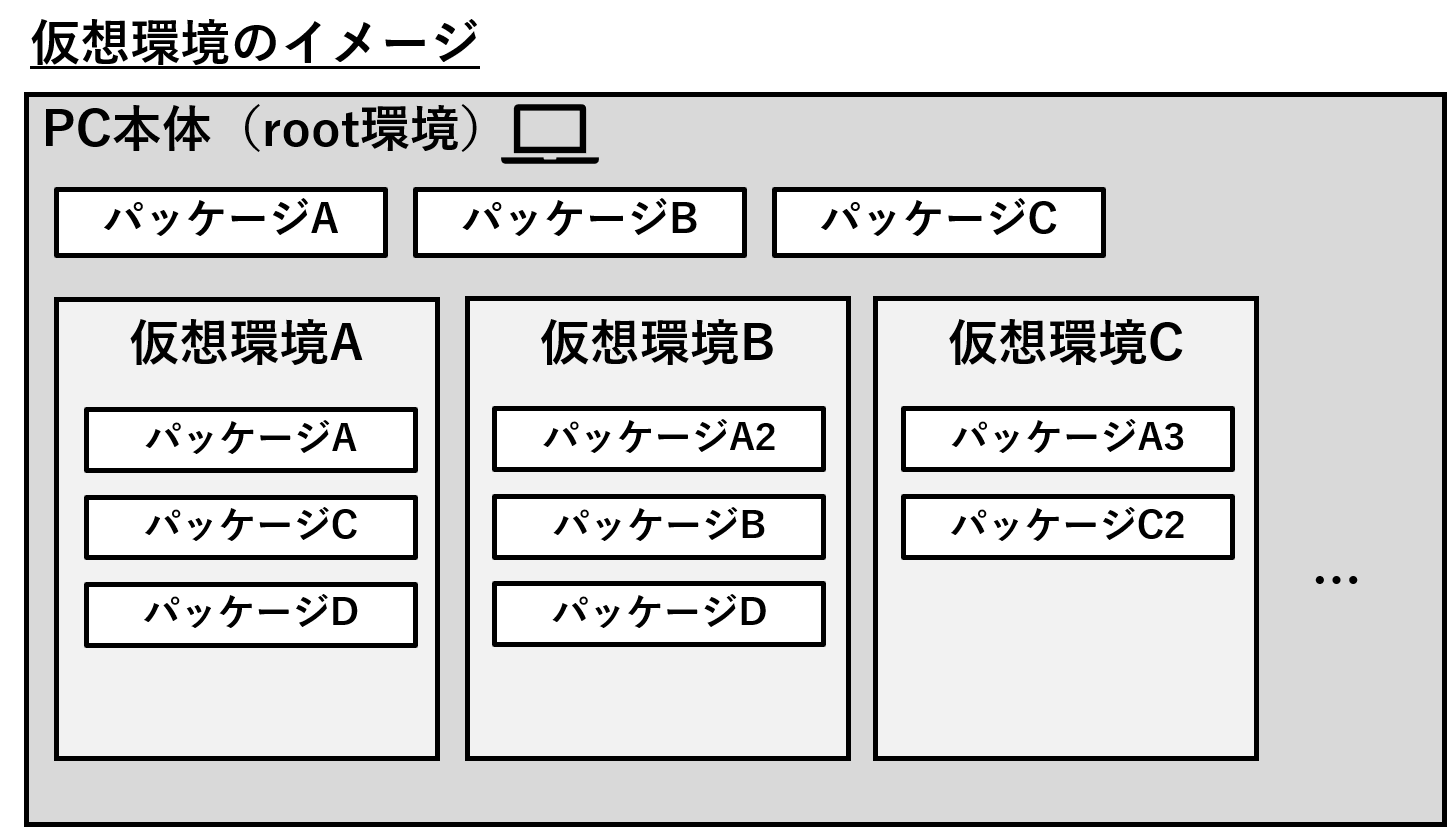
仮想環境を作成する目的は主に以下の2つです。
- 仮のパソコン(=仮想環境)の中だけで作業を行うことで、やり直しがきくようになります。仮想環境を作成すれば、何か不具合があった時にその仮想環境をリセットしてもう一度クリーンな状態から始めることが簡単にできるようになります。
- プロジェクトの管理がしやすくなります。あるAプロジェクトではAバージョンのパッケージを使用したいけどBプロジェクトではBバージョンのパッケージを使いたい、という場面がよくあります。この時PythonやPythonパッケージのバージョンを揃えておかないと機能しないことがあるため、できればプロジェクトごとに必要なパッケージを整理する必要があります。プロジェクトごとに仮想環境を立てることで、そうした管理を楽に行うことができるようになります。
仮想環境を作成しないと後にエラーのもととなりますので、しっかりと構築してからPythonを触るようにしましょう。
②「Anaconda」を導入する
プログラミング初学者にとって最も理解につまずくところが仮想環境の構築です。pip+virtualenv、pipenv、Anaconda…など、様々な方法が紹介されており、私も初めのころは手探りで試してかなり苦労しました。
データ分析を主目的とするなら、プログラミング初学者でも理解しやすいAnacondaを使用した構築をオススメします。
AnacondaはPythonに加えて、データ分析に必要なライブラリやエディタをまとめたパッケージのことです。データ分析を主目的に行うのであれば、Anaconda環境でほとんど完結させることができます。導入の仕方が簡単なだけでなく、GUI上で基本的なセットアップができるので、初学者でも直観的に理解しやすく、環境構築にかかる時間を短縮することができます。

導入方法はWindowsとMacで若干異なります。以下に導入方法に参考になるURLを掲載しました。または実際に動作を確認するのが効果的なことから、動画教材(後述)の利用もおすすめいたします。
また、仮想環境はANACONDA NAVIGATORというものを使って作成します。作成は以下のようにして行うことができます。

➂「Jupyter Lab」でコードを書く
環境構築の時点でエディタも用意します。エディタとはプログラムを書くノートのようなもので、Anacondaにも最初から用意されています。その中で私はJupyter Labを使うことをオススメします。Jupyter Labを使用すれば、コードの結果を都度確認でき、試行錯誤して分析できます(これをインタラクティブといいます)。
Jupyter Notebookという名前のツールもあり、これも大変よく使用されています。Jupyter LabはこのJupyter Notebookの後継であり、Jupyter NotebookでできることはJupyter Labでもできるため、これから使用する場合は「Lab」のほうがよいでしょう。
ANACONDA NAVIGATORを起動して、Jupyter Labは次のようにして使用できます。

➃環境構築不要の「Google Colaboratory」を使用して、すぐにデータ分析を始める
「環境構築とかに時間とられたくない!とりあえず早く分析したい!」といった方にGoogle Colaboratoryはかなりおすすめです。便利なので私も結構普段使いしています。
Google Colaboratoryを使用すれば、特に何もインストールすることなく、ブラウザ上で簡単に分析を始めることができます。ブラウザとGoogleアカウントさえあればドキュメントやスプレッドシートを始めるような感覚ですぐに分析を始められるので、これほど楽な環境構築はありません。しかも無料です。

一般的なJupyter Notebookの形式で記述することができ、Pythonを用いたデータ分析に必要な環境はほぼ整っています。
さらに機械学習の学習速度をサポートするハイスペックなGPUも使用できるため、気軽に機械学習を行うことができます。
もちろん、メモリや使用時間に制限はあり、大規模なデータや計算は行えない場合があります。しかしPythonでデータ分析を初めて学ぶ人にとっては十分すぎる環境なのは間違いありません。
設定や使い方はこちらの記事が大変参考になります。
ステップ3:Pythonの基本を覚える
次に、ステップ2で用意した環境を利用して、Pythonの基本的な書き方を学習します。このステップを行うことで、データ分析の見本となるコードに書いてある内容を理解できるようになります。
Pythonの基本とは、例えば以下の内容のことを指します。
- 数値や文字列の演算
- if文を用いた制御構文・条件分岐
- for文、while文を使用した繰り返し処理
- 関数の作成
- 変数のスコープの理解
- オブジェクト指向の理解(クラス、プロパティ、メソッド、継承、カプセル化、ポリモーフィズム)
- リスト、タプル、セット、辞書の意味と使い方
- Map, filter, lambda
- リスト内包表記
このステップにおけるポイントは、頭の中で完璧に理解しようとして時間をかけすぎないことです。文法について一つ一つ完璧にしていくよりも、分析の過程でコードを書いているときのほうが断然身につきます。広く浅くの程度(書いてあることが読める程度)になったら、次のステップに進むと良いです。
文法の理解に関しては以下のサービス・web記事によくまとまっています。私はProgateというサービスを利用して文法を勉強しました。
Web記事
オンラインサービス
ステップ4:主要なライブラリをマスターする
ライブラリとは、その用途ごとに関数など便利なプログラムがまとめられたもののことを指します。このライブラリが豊富に存在するおかげで、一から自分で実装しなくても統計分析から機械学習まで幅広い分析を手軽に行うことができるようになります。
Pythonでデータ分析をする場合、以下の4つは必ず使うことになるであろうライブラリです。避けては通れないライブラリなので、まず初めにおさえておくとよいです。
ライブラリ | 使用用途 |
|---|---|
pandas | データ分析・解析用のライブラリ。データの読み込みや加工などの前処理、統計量の表示を行うことができる。 |
NumPy | 数値計算用のライブラリ。簡単な表記で高速な行列演算をサポートしてくれるため機械学習で使うことが多いです。 |
Matplotlib | データ可視化用のライブラリ。グラフの描画や画像の表示、簡単なアニメーションの作成を行うことができます。 |
scikit-learn | 機械学習用のライブラリ。様々な機械学習の手法を用いて学習モデルを作成し、予測や分類に適応することができます。また単に機械学習を行うだけでなく、訓練データとテストデータへの分割やスケーリングなどの前処理もscikit-learnで行うことができます。 |
基本的に分析の過程では、これらのライブラリを組み合わせたり、これらを土台とした他のライブラリを使用することになります。そのため本や動画教材にある「Numpy入門」や「Pandas入門」といった章も気を抜かず隅々まで取り組むべきです。(私はNumpyをおろそかにしていたせいで後にかなり苦労しました。)
学習の仕方については、データ分析用の教材に合わせて載せられていることが多いです。後述のおすすめ教材にも、これらライブラリの使い方は基本的に解説されています。
ステップ5:データ分析の一連の流れを把握し、写経する
Pythonの基本の確認、主要ライブラリの使い方を学んだら、次は実際にデータを分析の見本となるコードを用意し、まとめて書き写してみます。実際に書いてみることで、今までのステップで学んだことがデータ分析の中でどのように機能するか、というのを鮮明に理解できます。
このとき、ただ書き写すだけではなく、書き写そうとしている分析の全体の流れを先に入れてから写経すると良いです。その理由は主に以下の3点です。
- データの分析手順に関して理解が深まるから。
- 分析手順のフレームを手に入れることができ、別の似た分析の時に使いまわせるから。(その結果「何から手を付けよう」といった時間のロスを減らせる。)
- 思考停止の写経にならず、コードの役割を理解しながら書けるから。
例えば以下は機械学習を用いた分析の流れの一例です。サンプルコードをこのように分け、それぞれのパートにおけるライブラリを書き出すことで、分析の全体像が把握でき、「どのときに何を使うべきか」を把握しやすくなります。(実際はもっと細分化します。)

この写経を行うにあたって、私は以下の2パターンの方法を使っていました。
- Udemyの教材で習ったコードを使用する。
- Kaggleの「Titanic」と「House Prices」のNotebook(or Kernel)を使用する。
このうち②のKaggleとはコミュニティサイトのことで、データ分析に関する様々なコンペティションが開かれていることで有名です。その中でも特に「Titanic」と「House Prices」は日本語記事も多く参考になる分析例がたくさんあるので初学者が写経するのにオススメです。Kaggleの詳しい概要や始め方はこちらの記事にまとめられています。
ステップ6:自分で一から分析する
最後にこれまでの学習を活かし、データの収集や前処理、分析の流れを自分でやってみます。一度一人でやりきることによって、自走力がかなり身につくようになります。
ここでのポイントは、今まで触れたことのないデータを分析することです。なぜなら、今後分析していく個別具体的なデータへの対応力は、本で読んだからといって身につけられるものではなく、実践して初めて身につけられるものだからです。そしてこれは、一度実践して初めて痛感するものなので、ぜひ未知のデータにチャレンジしていただきたいです。
不安であれば、Kaggleの「Titanic」はステップ5で行い、「House Prices」を本ステップ用に残しておくのも一つの選択肢です。自分で必死に考えてやり切った後に、先人たちの素晴らしいコードを見ると、自分の不足している部分が露骨に表れて非常に良い勉強になります。
さらに勉強の効率化を上げる2つのポイント
上記6ステップの効率をさらに上げるポイントは、「動画教材」と「相談相手の存在」です。
➀動画教材を活用する
動画教材は、最初は特に、本の2倍の速度での学習を可能にしてくれると考えています。なぜなら本の場合、「書いてあることから何をすればいいか理解する」→「書き写す」という流れになり、初学者はこの「理解する」パートにかなりのエネルギーを割かないといけません。しかし動画教材の場合、実際に動かしている場面を見ることができるため、この「理解する」パートの負担がかなり軽減されるからです。
Pythonでデータ分析を学ぶために、質の高い動画教材が多数存在しています。動画教材を購入する場として、私はUdemyというオンラインの学習教材を提供するサービスをよく利用しています。以下は私が実際に使用してよかったと感じた動画です。
もちろん、本で学習することも重要です。本はコンテンツが凝縮されているだけでなく、動画になっていない研究内容などは活字で読み解く必要があるので、本から学ぶ経験も必要不可欠です。
しかしPythonでデータ分析を学習するその入りとして、動画教材は一番ミスが少なく理解しやすいと考えています。
以下は弊社が過去に開催したPythonセミナー動画になります。参考書では理解しづらい環境構築やデータ分析について分かりやすく解説しておりますので、是非ご視聴ください。
https://www.youtube.com/watch?v=pEtHYeuXx4Y&t=243s
https://www.youtube.com/watch?v=89f6dz6SuzY
②わからないことを気軽に相談できる人を見つける
個人的には相談できる人の存在がかなりクリティカルでした。私の場合、職場のメンターがこれに当たります。
わからないことがあって一人で悶々としていると、時間はすぐになくなります。自分の頭とネットにしかリソースがないと「実はもっと調べればわかりやすいやり方があるはずだ」、「もう少し考えればわかるはずだ」というような終わりの見えない泥沼に最初は陥りがちです。
このようなとき、自分よりスキルのある人に相談できると、以下のことが期待でき、時間を浪費しなくて済むようになります。
- すぐに解決策がわかる
- その場で解決策が出なくても、今までとは違う妥当性のある切り口で検討できるようになる
- 「その人でも解決できないならしょうがない」と踏ん切りがつき、別の方法を試すことに切り替えられる
最初私は一人ですべてを行おうとした結果、かなりの時間を無駄にしました。これから始める方は相談相手を見つけ、私の二の舞を演じないでください。
データ分析を始めるにあたって役に立つ教材
本記事で紹介した教材をまとめておきます。知識ゼロから学習をした私からして、特に初学者の方には使いやすい教材たちなのではなかと思います。
| 教材名 | 形式 | 特徴 |
|---|---|---|
| Progate(Python) | オンラインサービス | Pythonの基本的な部分を問題を解きながら学ぶことができます。 |
| Aidemy | オンラインサービス | 基本だけでなく、AI関連の他のコースも用意されています。 |
| ドットインストール | 動画 | 3分以内の動画をみて学習を進められます。 |
| Tommy blog | web記事 | Pythonの基本的な部分がまとめられています。 |
| 米国データサイエンティストのブログ | web記事 | Pythonにdockerを使用した環境構築の方法から主要ライブラリの使い方まで幅広くまとめられています。 |
| 【世界で5万人が受講】実践 Python データサイエンス | 動画 | 実践を交えながらデータ分析に必要なライブラリを学べます。網羅性も高いです。 |
| Pythonで学習:scikit-learnで学ぶ識別入門 | 動画 | 実践例豊富でscikit-learnを使用した機械学習の概観を知れます。 |
| 動画 | CNN、RNN、VAE、GANなど、AIに関する技術を幅広く学べます。Pythonの基礎から触れているので初学者にもわかりゃすいです。 |
また、6ステップを終えたら、下記コンテンツにも取り組むとさらに世界が広がると思います。
| 教材名 | 形式 | 特徴 |
|---|---|---|
| Python実践データ分析100本ノック | 本 | 現場の実務に即した例題が豊富で特に前処理の大変さがわかります。練習教材として使用しやすいです。 |
| 機械学習のエッセンス | 本 | 機械学習に使う数学にページが割かれており、scikit-learnなどのライブラリに頼らない実装がされてるので、機械学習の要点が理解しやすいです。 |
| Pythonで始める機械学習 | 本 | scikit-learnを使用した機械学習を深く学べます。事前に機械学習の入門書を読んでおくと、理解の助けになると思います。 |
| ゼロから作るDeep Learning | 本 | ディープラーニングの中で何が行われているかイメージがつくようになります。初学者向けです。 |
| はじめてのパターン認識 | 本 | 数式がたくさんあるので文系からしたら名前のような優しさを感じにくいですが、機械学習の勉強にとても良い本です。 |
まとめ
今回はPythonでデータ分析を学習するための6ステップを、私の経験を踏まえてご紹介しました。
- ステップ1:学習すべき3要素を知る
- ステップ2:環境構築をする
- ステップ3:Pythonの基本を覚える
- ステップ4:主要なライブラリをマスターする
- ステップ5:データ分析の一連の流れを把握し、写経する
- ステップ6:自分で一から分析する
この6ステップに沿うことで、初学者でも迷うことなく学習を進めることができ、自走する力が身につくはずです。
プログラミングもデータ分析も、量をやればやるだけ身につく分野です。そのため学習の入口で不必要につまずき時間をロスすることは大変もったいないです。いち早く自走する力を身に着け、どんどん分析に取り組んでもらえればと思います!
データのことなら、高い技術力とビジネス理解を融合させる私たちにご相談ください。
当社では、データ分析/視覚化/データ基盤コンサルティング・PoC支援に加え、ビジュアルアナリティクス、ダッシュボードレビュー研修、役員・管理職向け研修などのトレーニングを提供しています。組織に根付くデータ活用戦略立案の伴走をしています。




