
データの時代において、膨大な情報を効果的に管理し、価値あるインサイトを得るためには、適切な構造と組織が必要です。ここで登場するのが「データモデリング」です。
データモデリングは、情報やデータを論理的に組み立て、関係や属性を明確に定義するプロセスです。この記事では、データモデリングの基本的な概念から実践的な手法、そしてなぜデータモデリングがビジネスにおいて不可欠なのかについて探っていきます。
データモデリングを行うことで、データの一貫性、データの品質、効率的なデータ処理が可能となり、ビジネスの意思決定や戦略的な洞察を支える重要な基盤を作り上げることができます。
例えば、以下のようなデータ分析・可視化のユースケース支援のようなものでは、ユースケース構築と同時にデータモデリングまでを行うと、コンセプトとデータがに高度に絡み合い、後々非常に便利でかつ価値をもたらします。
株式会社ユーザベース様|データ分析基盤構築とデータカルチャーの融合で更なる競争力獲得を目指す
1.データモデリングとは?
データモデリングとは、簡単に言えば、実世界のデータやプロセスをデータベースにうまくマッピングするための設計図を作成する作業です。
情報やデータをどのように整理し、構造化し、関連付けるかを視覚的に表現するプロセスのことを指します。
データマネジメントを推進するデータビズラボの研修資料をダウンロードする
2.データモデリングの3つの主な目的
データモデリングを行う時、さまざまな目的があるのですが、以下で主要なものを挙げます。
データの整理と理解
データモデリングは、複雑なデータを管理可能な構造に整理するためのフレームワークです。これにより、データの内容、構造、関連性が明確になり、データの理解が容易になります。
データ品質の一貫性と品質の担保
データモデリングを通じて適切なデータ構造を定義することで、データの一貫性と品質が確保されます。データの不整合や重複が減少し、信頼性の高い情報を得ることが可能となります。
データ品質を上げるために、データモデリングを行うということもあります。
データ品質とは?品質評価項目や品質を向上させるための実務的対策を解説
効率的なデータマネジメント
データモデリングは、データの追加、更新、検索、削除といった操作を効率的に行うための基盤を維持します。良好に設計されたデータモデルは、データベースのパフォーマンスを向上させ、管理を容易にします。
以下の記事も参考にされてください。
データマネジメントとは?導入のメリットや実践的な進め方を解説
3.データモデリングの手順
データモデリングはビジネス要件からスタートして3段階に分けて徐々に詳細な記述を進めていきます。各段階はそれぞれ概念データモデル、論理データモデル、物理データモデルと呼ばれます。以下でデータモデリングの進め方に沿って各モデルの成果イメージを説明していきます。
Step1 要件収集
最初のステップは、ビジネス要件を理解し、その要件を満たすためにどのようなデータが必要かを特定することです。このステップでは、ビジネスユーザー、ステークホルダー、IT専門家との対話が重要となります。
Step2 概念データモデルの作成
概念データモデルは、主要なエンティティ(データを構成する項目)、その属性(エンティティの特性や特徴)、およびそれらの間の関係を特定するものです。
簡単に言えば、収集したビジネス要件から「顧客」や「注文」といった概念の関係性を図示するものです。この段階ではデータの整理よりもビジネス上の概念の整理と合意が目的とするため、データ型や物理的構造は考慮しません。概念データモデルは、エンティティとそれらの間の関連を示すER図(Entity-Relationship Diagram)や、UML(Unified Modeling Language)のクラス図などが使用されます。以下のような成果を持ってビジネスユーザーをはじめとした各ステークホルダーと認識がすりあえば概念データモデルの作成は完了です。
▼概念データモデルイメージ
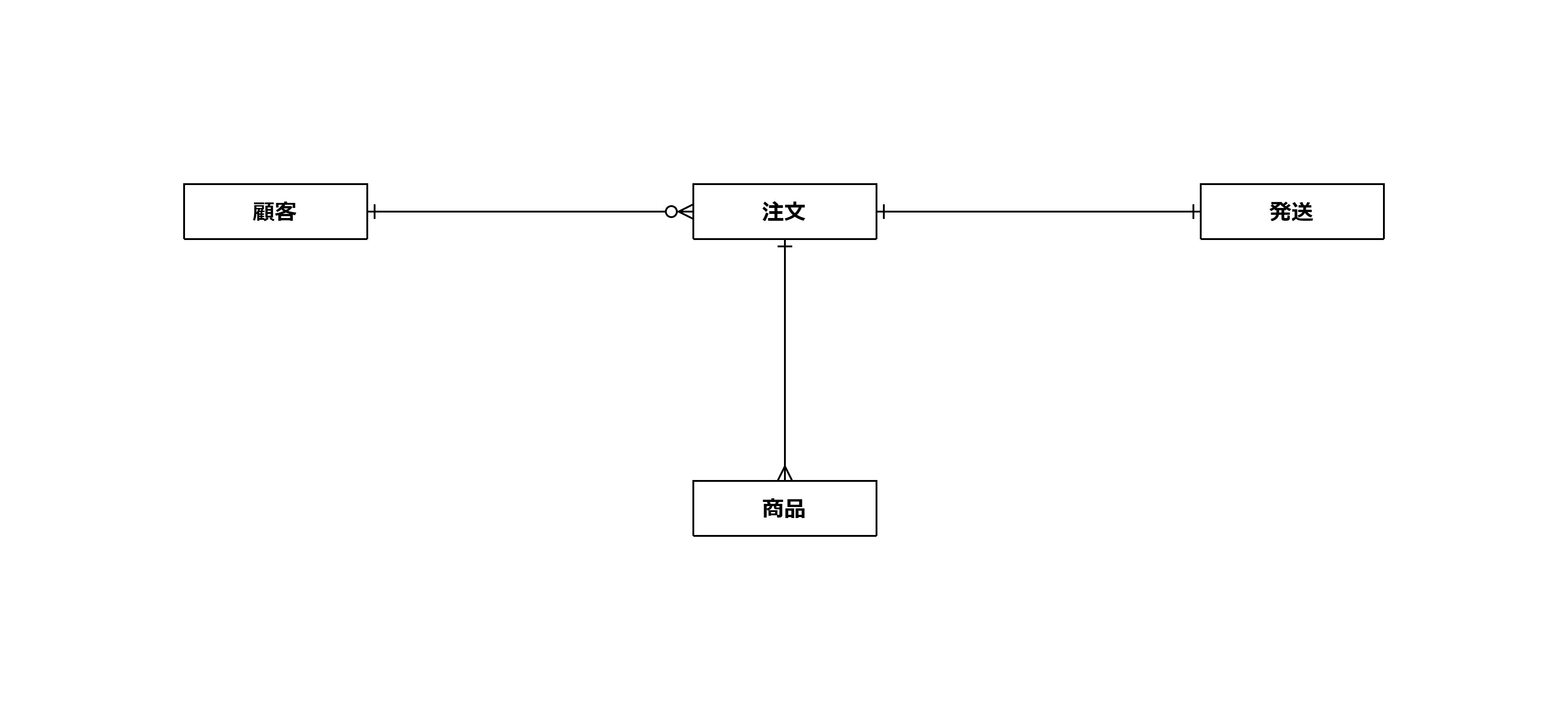
概念データモデルの作成手順は、具体的には以下のようになります。
エンティティの特定
業務を理解し、その中での主要なエンティティ(またはオブジェクト)を識別します。エンティティはビジネスや組織に存在する重要なもの(例:顧客、商品、注文)を指します。
エンティティ間の関係の特定
異なるエンティティ間の関係を定義します。これらの関係は、ビジネスルールとプロセスを反映しているものになります。
主要属性の特定
エンティティに関連する主要な属性を特定します。たとえば、顧客エンティティには「氏名」や「連絡先情報」などの属性が含まれます。
ビジネスルール(業務ルール)の定義(ない場合)
各エンティティと属性、それらの関連性に対するビジネスルールを定義します。ビジネスルールは、ビジネスの運営方法、業務の進行方法、およびそのビジネス内でデータがどのように処理および管理されるべきかを決定する、ビジネスのポリシーや規定を表現したものです。
※ビジネスルール(業務ルール)
ビジネスルールは通常、以下のような形式で表現されます。
- 条件文:「もしXが起こるならば、Yを行う」
- 制約:「Aは常にBでなければならない」
- アクション:「Cが起こったとき、Dを行う」
具体的な例としては、次のようなものがあります。
- 「18歳未満の顧客はアルコールを購入できない」
- 「全ての顧客は一意の顧客IDを持つ必要がある」
- 「注文がキャンセルされた場合、顧客には全額返金される」
ここで言うビジネスルールは、システムの振る舞いを制御し、システムがビジネスの目標を達成するための道筋を提供するものです。これらのルールは、システム開発の過程でデータモデル、ワークフロー、ビジネスロジックなどに反映されるため、概念データモデリング作成において非常に重要です。
概念データモデル作成時の一般的な成果物
- エンティティのリスト: ビジネスや組織に存在する重要なもの(例:顧客、商品、注文)を表すエンティティのリスト。
属性のリスト: 各エンティティに関連する主要な属性(特性や性質)のリスト。例えば、"顧客"エンティティの場合、"名前"や"住所"などが属性になります。
エンティティ間の関連性: エンティティ間の関係性が定義されています。これにより、エンティティがどのように相互作用し、依存関係がどのように構築されているかを理解します。この関連性は、一対一、一対多、または多対多といった形式を取ることがあります。
ビジネスルール: エンティティと属性、それらの関連性に対するビジネスルール(なければこのタイミングで作成します)。これらのルールは、データがどのように処理され、管理されるべきかを示しています。
概念データモデル図: 上記の全ての情報を視覚的に表現した図があります。これは通常、エンティティ-関係図(ER図)の形式を取り、エンティティ、属性、それらの間の関係を示しています。
これらの成果物は、ビジネスステークホルダーとITスタッフとの間でのコミュニケーションを改善し、共通の理解を促進します。また、概念データモデルは、より具体的な物理データモデルや論理データモデルの基礎ともなります。
概念データモデルは、ビジネスのキーエンティティとそれらの間の関係を高レベルで捉えることに重点を置いています。それは特定の技術やデータベースシステムに依存せず、ビジネスの全体的な視点を提供するために作成されます。
Step3 論理データモデルの作成
論理データモデルでは、概念データモデルをさらに詳細にし、具体的なデータ型や制約を定義します。このステップでは、全てのエンティティ、属性、関係をより具体的に定義し、実際のデータベース設計に近づけます。以下のようなイメージです。
▼論理データモデルイメージ
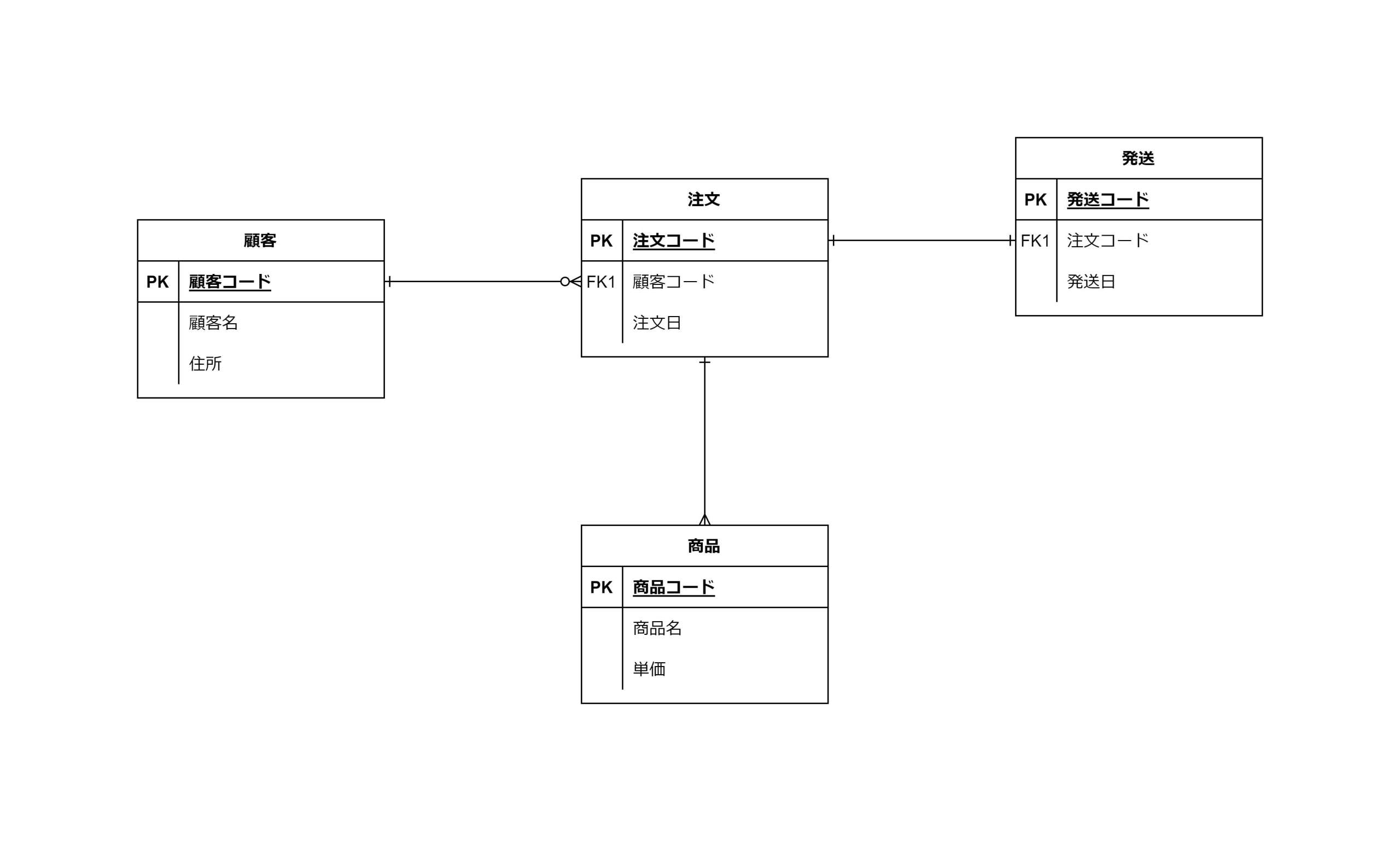
論理データモデルを作成するための一般的な手順は以下のとおりです。
キー属性の識別
それぞれのエンティティについて、一意にそのエンティティを識別できるキー属性を定義します。これは主キーとして知られ、各エンティティ内で一意でなければなりません。
正規化
データの重複を排除し、データの一貫性を保つために正規化を行いますす。正規化はデータ構造の効率性と一貫性を向上させ、更新異常を防ぎます。
モデルの検証と調整
論理データモデルが完全に定義されたら、ビジネスステークホルダーやエンドユーザーと共にモデルをレビューし、必要な修正や調整を行います。
ドキュメンテーション
最後に、論理データモデルの詳細をドキュメントにまとめます。
論理データモデルの作成時の一般的な成果物
キー属性の定義: 各エンティティを一意に識別するためのキー属性。
ビジネスルール: データベースに適用されるビジネスルールの詳細な説明。これには、属性値の範囲、デフォルト値、必須またはオプションの属性、エンティティ間の関連性の制約などが含まれることがあります。
論理データモデル図: 上記の全ての要素を視覚的に示す図。これは通常、EER図やUML図の形式を取ります。
論理データモデルは特定の技術やツールからは独立していますが、これらの成果物は、システム設計者、開発者、データベース管理者などの技術チームがシステムやデータベースの設計を行うための基盤となります。
また、これらは物理データモデルの作成の基礎となります。
Step4 物理データモデルの作成
物理データモデルでは、論理データモデルを特定のデータベースシステムで実装可能な形に変換します。この段階では、具体的なテーブル構造、インデックス、ストレージの配置、パフォーマンスに影響を与える他の要素を考慮します。
▼物理データモデルイメージ
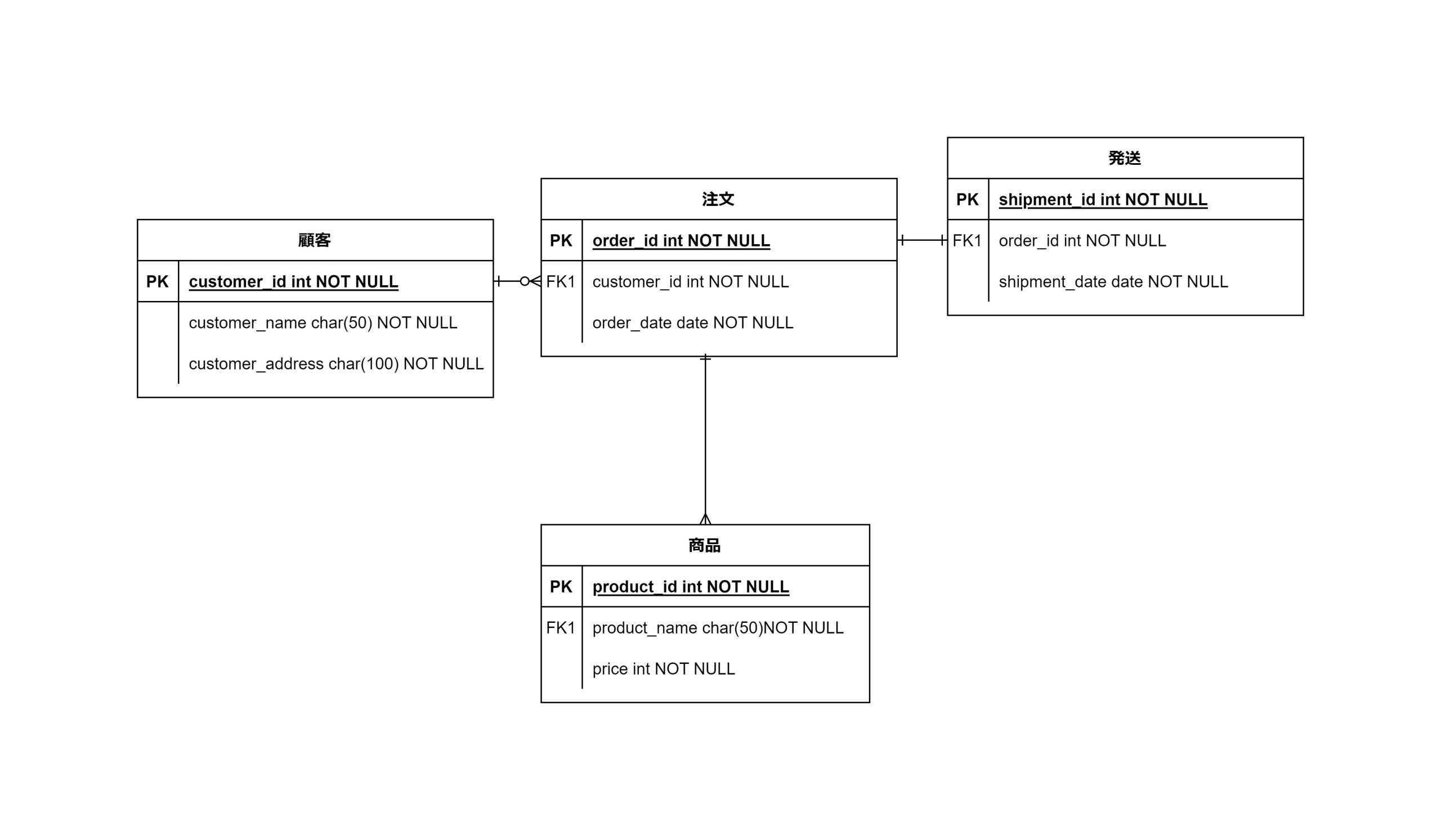
物理データモデルの作成手順は以下のようなイメージです。
論理データモデルからの変換
論理データモデルが物理データモデルの起点となります。エンティティ、属性、リレーションシップは、具体的なテーブル、列、キー、インデックスなどに変換されます。
DBMSの特性と制約の考慮
特定のDBMSの特性と制約を考慮に入れます。これには、データ型、ストレージ容量、パフォーマンス要件、セキュリティ要件などが含まれます。
データベースの物理構造の定義
データベースの物理構造を定義します。これには、テーブルスペース、クラスタ、インデックス、ストレージパラメータなどが含まれます。
データベーススキーマの生成
DBMSに適した形式でデータベーススキーマを生成します。スキーマはデータベースの構造と制約を定義したものです。
最適化
パフォーマンス要件に基づいてデータベースの最適化を行います。これには、インデックスの使用、パーティショニングの戦略、データベースの正規化や非正規化などが含まれます。
データ移行計画の作成
既存のデータがある場合、そのデータを新しい物理データモデルにどのように移行するかの計画を作成します。
ドキュメンテーション
最後に、物理データモデルの詳細をドキュメントにまとめます。これには、テーブル定義、データ型、インデックス、リレーションシップ、その他の物理的な特性が含まれます。
物理データモデル作成時の成果物
物理データベーススキーマ: 特定のデータベース管理システム(DBMS)に対応する、テーブル、ビュー、インデックス、制約、トリガーなどの詳細な定義。
DDLスクリプト: データベース定義言語(DDL)スクリプトを用いて、物理データベーススキーマを作成する。これにはテーブルの作成、インデックスの作成、ビューの作成、制約の設定などが含まれます。
ストレージ構造: テーブルスペース、パーティショニング、クラスタリングなどの物理的なデータベースの配置に関する詳細。
最適化戦略: データベースのパフォーマンスを最適化するための戦略。これには、インデックス使用戦略、パーティショニング戦略、クエリ最適化戦略なども含みます。
データ移行計画: 既存のデータを新しい物理データベーススキーマに移行するための詳細な計画。この計画にはデータクレンジング、データ変換、データロードのプロセスなども含まれます。
ドキュメンテーション: 物理データモデルの詳細を記述したドキュメンテーション。これには、テーブル定義、インデックス定義、ストレージ構造、最適化戦略、データ移行計画などが含まれます。
Step5 データモデルの検証
データモデルがビジネス要件を適切に満たしているか確認します。必要に応じて、フィードバックを元にモデルを修正します。
Step6 データモデルの実装
最後に、作成した物理データモデルに基づいてデータベースを構築または改善します。
また、データモデリングは反復的なプロセスであり、ビジネスの要件が変わるとデータモデルもそれに応じて更新する必要があります。そのため、定期的なレビューと更新が必要となります。このレビューや更新プロセスは、通常、データガバナンスの領域でカバーすることが多いです。
参考:『データガバナンスとはデータマネジメントを監督すること』
4.データモデリングツール
データモデリングはどのようなツールを使ってもよいのですが、特化したツールを使えるとさらに便利です。以下に一般的に使用されるいくつかのデータモデリングツールを紹介します。
ERwin Data Modeler
ERwin Data Modelerは、エンティティ関係(ER)モデリングに特化した人気のあるツールです。直感的なインターフェースと豊富な機能を提供し、様々なデータモデルを作成、管理、ドキュメント化することができます。
Oracle SQL Developer Data Modeler
Oracle SQL Developer Data Modelerは、Oracleデータベースに特化したデータモデリングツールです。Oracleのデータベース環境にシームレスに統合し、データベース設計、データモデルの作成、逆エンジニアリングなどの機能を提供します。
SAP PowerDesigner
多機能なデータモデリングツールであり、様々なデータモデリングアプローチ(ERモデリング、UMLモデリングなど)をサポートしています。データベース設計、ビジネスプロセスモデリング、データウェアハウス設計など、幅広い用途に使用されます。
IBM InfoSphere Data Architect
大規模なデータモデリングプロジェクト向けに設計されたツールです。異なるデータベース環境やテクノロジーに対応し、データモデルの作成、分析、比較、ドキュメント化をサポートします。
ER/Studio
ER/Studioは、データモデリングとメタデータ管理のための包括的なツールです。ビジネスルールの管理、データ品質の評価、データラインエージングなどの機能があり、複雑なデータ環境でのデータモデリングを効率化します。
5.データモデリングを始めるためのオンラインリソースと学習資料
いろいろツールはあるものの、どのようにこの領域の知識をキャッチアップしていけばよいかわからないという方は多いと思います。そこで、以下に学習の第一歩目としてのおすすめリソースや学習資料を紹介します。自身の学習スタイルや目的に合わせて、適切なリソースを選んで学習を進めてみてください。
マイクロソフトの公式ドキュメント
マイクロソフトの公式ドキュメントでは、データモデリングの基本概念や目的、手法について詳しく解説されています。以下のリンクからアクセスできます。
https://learn.microsoft.com/ja-jp/training/modules/modern-analytics-data-modeling/
Qiitaの記事
技術系の情報共有プラットフォームには、データモデリングに関する入門記事が多数投稿されています。さまざまな視点からデータモデリングについて学ぶことができます。以下のリンクからアクセスできます。
Udemyのオンラインコース
Udemyはオンライン学習プラットフォームで、データモデリングに関する入門コースが提供されています。実践的な手法やツールの使用方法を学ぶことができます。以下のリンクからアクセスできます。
まとめ
データモデリングは、組織やシステム内のデータの構造と関係を理解し、正確かつ効果的なデータ管理を実現するための重要なプロセスです。
正確なデータモデルを作成し、柔軟性と変更管理の実現を図ることで、ビジネス上の課題に効果的に対処することができます。データモデリングは、組織やプロジェクトの成功において欠かせない要素となるため、適切な知識とツールを駆使して取り組むことが重要です。
データビズラボではデータモデリング支援サービスもご提供しております。
データの活用にお悩みの場合はデータビズラボまでお問い合わせください。
https://data-viz-lab.com/datamodeling
データマネジメントとは?導入のメリットや実践的な進め方を解説




