



データレイクは安価で大容量のデータ分析基盤として注目されています。一方でデータウェアハウスとの違いがわかりづらく、2つの概念を混同されている方もいらっしゃるかと思います。
本記事では、データレイクとデータウェアハウスの違いについて以下の観点から詳細に比較していきます。
- どんなニーズを満たすことができるのか
- どんなデータを格納できるのか
- 分析者は誰なのか
- コストはどれくらいかかるのか
- どんな注意点があるのか
- 実際に導入するには
最後までお読みいただくことでデータレイクやデータウェアハウスといったデータ分析基盤への理解が深まり、どんな分析基盤が自社にとって最適か判断することができるようになります。
データレイクやデータウェアハウスの構築・運用に関して弊社のサービスにご関心がある場合は是非こちらをご覧ください。
目次
1.データレイクとデータウェアハウスの違い
データレイクとデータウェアハウスの特徴を5つの軸で比較するとこのようにまとめることができます。
データレイク | データウェアハウス | |
格納されるデータ |
|
|
データを使う目的 |
|
|
コスト |
|
|
ユーザー |
|
|
注意点 |
|
|
本章ではデータレイクとよく混同されるデータウェアハウスとの基本的な特徴の違いについて解説します。
1-1.データレイクは倉庫、データウェアハウスは物流センター
データレイクはデータウェアハウスと比較することで直感的に理解しやすくなります。イメージとしては、データレイクが「何でも置いておくことができる倉庫」、データウェアハウスが「最終消費者に届けるために整備された物流センター」のように捉えるとわかりやすいです。
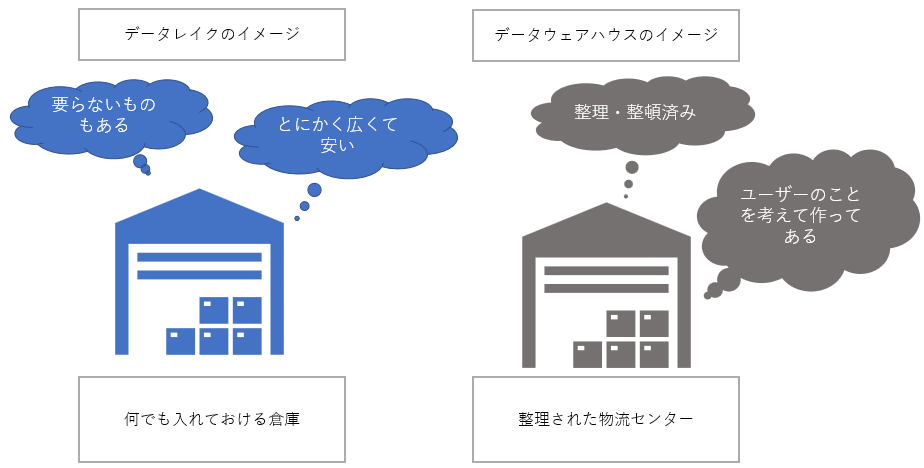
データウェアハウスはデータを使うユーザーの目線に立って使いやすいように構築されているため、整理・整頓の際にコストがかかってしまいます。一方でデータレイクはそうしたコストはかかりませんが、ひたすらデータを詰め込む目的で作られているので、どこに何のデータがあるかわからなくなってしまうリスクも存在しています。
1-2.データレイクによって安価に大量の生データを分析できる
データレイクは生データをそのまま大量に貯えられるという特性から、以下の5つのニーズを満たすことができます。
- AI・機械学習を導入したい
- 非構造化データを活用したい
- データサイエンティストが探索的に分析できる環境が欲しい
- 低コストで分析基盤を作りたい
- 最新のデータを素早く分析したい
AI・機械学習を導入したい/非構造化データを活用したい
機械学習やAIを導入する際には、どんな分析手法を採用するかによってデータの前処理方法が変わるため、データサイエンティストが生データに直接アクセスできるほうが効率的です。また、データレイクにはテキストデータやセンサーデータ、画像データといった非構造化データもそのまま格納することができます。
それらのデータを用いて機械学習を行い、例えば以下のことを実現することができます。
- 大量の画像データと熱センサーデータを用いて、高精度な異常検知システムを製造ライン上に構築する
- モバイル機器やセンサー、カメラから送られてくる情報をAIに学習させ、IoTによる顧客利便性向上に役立てる
- アンケートの回答結果を大量に集計し、テキストマイニングによってインサイトを得る
データサイエンティストが探索的に分析できる環境が欲しい/最新のデータを素早く分析したい
DWHには、予め利用目的が定められたデータのみが集約されるため、どのように役立ててよいかわからないデータを探索して利用可能性を探る場合には、全てのデータが存在しているデータレイクを利用します。
また、データウェアハウスにデータを移すためには前処理をするタイムラグが生じるため、今すぐに新鮮なデータにアクセスしたい場合にはデータレイクの方が向いています。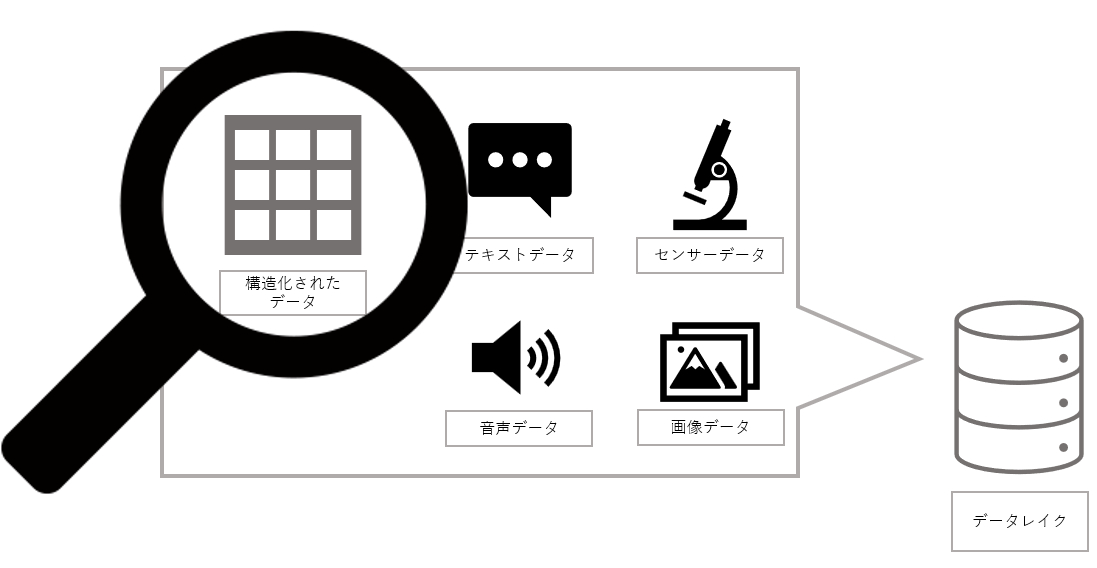
低コスト/低リスクで分析基盤を作りたい
データレイクを導入することで、データベースの負担を軽減し、データウェアハウスのストレージコストを下げることができます。
データベースでビッグデータを管理する場合、サーバーを増やして対応する以外に手段がありません。過去には、機器から送られてくる大量のデータを捌ききれずにサーバーが圧迫されたりエラーが発生するといった問題も起きたことがあります。たまったデータをデータレイクに吐き出すことでサーバーの負担を軽減できます。
データウェアハウスにビッグデータを貯める場合、データレイクよりデータを蓄えるためのストレージのコストが高いです。また、前処理を膨大なデータにかけた上で整理しなくてはならないので時間もかかります。そのため、まだ目的が定まっていない非構造化データを大量に入れておく場所としては不適切です。
データベースから過剰なデータをデータレイクに移し、分析に必要なデータをデータレイクから抽出してデータウェアハウスに送るという流れを作ることでこれらの問題を解決し、コストとリスクを下げた分析基盤の構築ができます。
データレイクのプロダクト
データレイクの主なプロダクト例としては、Hadoop、Azure、Amazon S3があります。
参考までに、こちらはAmazon S3とTableauを使った当社の事例になります。ぜひご覧ください。
広告クリエイティブダッシュボード構築支援(AWS(Redshift/S3)&Tableau Extensions API)
参考:非構造化データの一つであるテキストデータを使った分析についての記事
1-3.データウェアハウスによってデータをビジネスに役立てる
データウェアハウスは経営上の視点からデータを活用し、戦略を考えるためのデータ分析基盤です。データベースによってさまざまな種類のデータが貯蓄されていく中で、それらのデータを統合してビジネスに役立てるために生まれました。
データウェアハウスの4つの特徴
以下の4つの特徴があると1990年代にデータウェアハウスの概念を提唱したビル・インモン氏が定義しています。
- サブジェクト指向(subject oriented):活用目的に沿って整理されている
- 統合化(integrated):複数のデータソースから活用目的ごとに統合する
- 恒常的(nonvolatile):必要な時に過去のデータを遡って分析できる
- 時系列(time variant):データが時系列に並んでいる
従来のデータベースの課題となっていたデータ容量の限界をなくし、時系列・目的ごとに整理することで分析しやすくなります。
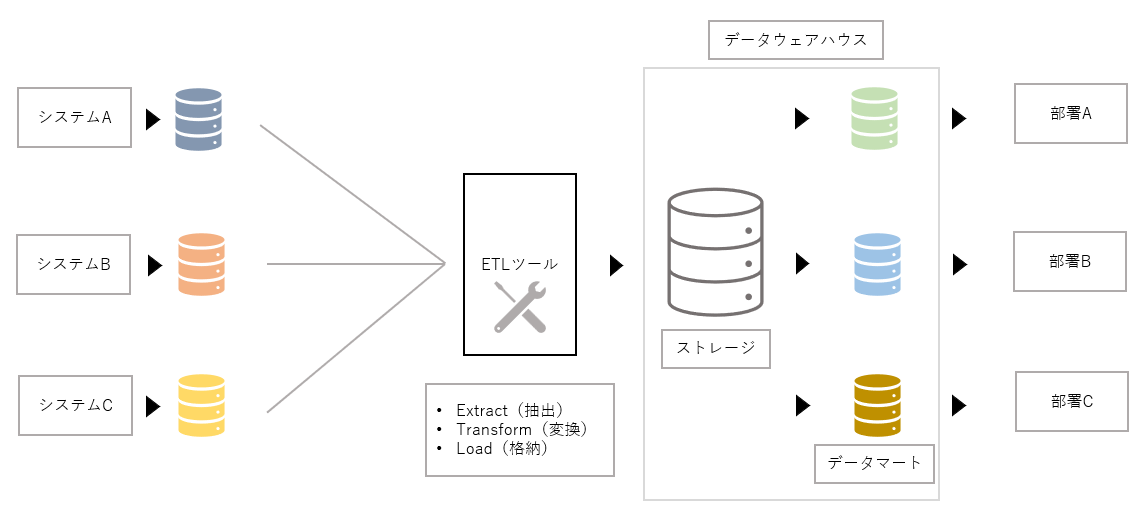
データの流れを示したイメージ図がこちらになります。
データウェアハウスのプロダクト
データウェアハウスの主なプロダクト例としては、SnowflakeやTeradataがあります。Snowflakeの詳細や使い所に関しては以下の記事にも詳細を書いています。
レイクハウスとは、データウェアハウスの生みの親であるビル・インモン氏が2017年頃に提唱した新しい概念でデータレイクとデータウェアハウスのいいとこ取りをするツールになります。最終的には以下の姿を目指しています。
- トランザクションをサポートして一貫性を保つ
- 同時接続ユーザー数の増加やデータ量の増加に応じてシステムがスケールアウトできる
- データレイクとデータウェアハウスでデータを二重持ちする必要なく、BIがデータソースに直接アクセスできる
- PythonやRのライブラリをAPIとして活用でき、直接データにつないで機械学習を実行できる
- コストを削減できる
- 非構造化データを正しく管理できる
つまり、「シンプルかつコスト効率もよく、膨大で様々な種類のデータに対応でき、様々なデータアプリケーションに対応できるデータ分析基盤がレイクハウスである」と言えます。しかし、現状まだまだ性能は低く、近代的なデータウェアハウスを上回ることができていません。
2.データレイクとデータウェアハウスの活用方法
具体的にデータレイクとデータウェアハウスそれぞれで実現できることと、データレイクとデータウェアハウスを併用して構築するイメージについてご紹介します。
2-1.データレイクとデータウェアハウスが必要となる状況
データレイクは以下の状況で必要とされる/効力を発揮すると言えます。
- 旧来のデータ分析基盤のコストが増大しており、新しい分析基盤を作ってコストを下げたい
- 大量の非構造化データを保有しており、今後の活用を検討している
- 社内にデータ分析専門の部署があり、予測モデルの構築やAIの活用のために生データを分析するニーズがある
一方でデータウェアハウスが必要とされる状況は以下です。
- データベースにデータが蓄積されているものの、ビジネスにデータが活用できていない
- 構造化されているデータのみ保有しており、非構造化データを持つ予定はない
- 部門間で異なるシステムを使っており、統合的なデータ分析基盤が必要とされている
以上から、データウェアハウスはこれからデータ分析を始める企業に向いており、データを使って経営に役立てたい場合に最適だと言えます。一方でデータレイクは既にデータ分析を一定実施している企業がデータウェアハウスの低コスト化を進めたい場合や、新たなサービスの開発にデータを役立てたい場合に必要です。
2-2.データレイクとデータウェアハウスで最新のデータ分析基盤を構築する
データウェアハウスやデータレイクは異なる役割を担っており、データの流れをパイプライン化することで最大の効果を発揮します。データレイクやデータウェアハウス、BIツールなどを活用することで統合的なデータ分析基盤を構築し、部署ごとのデータのサイロ化や分析の属人化を防ぐことができます。
データレイクとデータウェアハウスが組み込まれたデータアーキテクチャとしては以下のようなイメージができます。データレイクに各システムやデータソースからのデータが集約され、データウェアハウスに必要なデータが抽出、各部署はデータマートを使ってデータを可視化・分析するというのが一連の流れです。
データマネジメントやデータガバナンスの観点からも、共通のルールに基づいてデータを管理でき、高品質であることが保証されたデータを使って分析を進めることができます。

3.データレイクとデータウェアハウスそれぞれの注意点
データレイクとデータウェアハウスはそれぞれ注意点が存在しています。
3-1.データレイクは専門家が扱うべきである
データレイクは安価に大量のデータを保存しておけるため便利ですが、膨大なデータをそのまま格納するという特性上、注意点も存在しています。
- データの専門家でないと扱うのが難しい
- 「データの沼」とならないようにする
データの専門家でないと扱うのが難しい
生のデータがそのまま存在しているため、自分で前処理やデータの統合を行う必要があります。生データを扱う上では以下のように気を付けるポイントが多く、ビジネス担当者にはハードルが高いです。
- データの信頼性をどのように確かめるか
- データの統合はどのカラムをキーにして行うのか
- 表記ゆれやデータ型の修正・統一
「データの沼」になりやすい
データを格納する上でのルールを決めたり、格納したデータの特徴をメタデータとして記録したりしない場合、どこに何のデータがあるかわからないデータスワンプ(データの沼)状態になってしまいます。
加えて、誰にどこまでデータにアクセスする権限を与えるかなどのデータガバナンス上の取り決めも予めしておく必要があります。
データの検索性を担保し、沼化を避けるためにデータカタログを作成しておくとよいです。データカタログには以下4点のメタデータを整理して格納しましょう。
- 活用ノウハウに関する情報 (ビジネスメタデータ)
- データ仕様に関する情報 (アプリケーションメタデータ)
- データ品質に関する情報 (品質メタデータ)
- データ利用権限に関する情報 (セキュリティデータ)
3-2.データウェアハウスはコストの増大に注意する
データウェアハウスでは、以下2つのコストに注意しましょう。
- ストレージとしてのコスト
- 構築にかかる時間的なコスト
データを貯えるためのコストが高い
何度かご説明しているかと思いますが、データレイクの方がデータウェアハウスよりデータの貯蔵先としては安価です。データウェアハウスで全てのデータを蓄えようとすると、維持費が高額になってしまう場合があります。データレイクと併用することで、現状の分析に必要なデータのみを入れるようにしましょう。
構築に時間がかかる
ビジネスに役立てるためにどんなテーブルを作成するべきか、生データをどのように構造化し、統合するかなど考えるべきことが多く、最適なデータウェアハウスの構築には時間が必要です。様々な種類のデータがあればあるほどデータの持ち方が複雑化し、統合がうまくいっているか検証するプロセスも必要になります。
一方で、短時間でその場しのぎに構築したデータウェアハウスでは、最終的な活用のイメージが想定されていないため実際のビジネスが抱える課題を解決することができません。必要な時間を惜しまず、最適なデータウェアハウスの構築を行いましょう。
4.データレイクやデータウェアハウスを導入する上でのポイント
最適なデータレイクのプロダクトを選び、先進的なデータ分析基盤の構築を目指す際には以下の3つがポイントになります。
- ゴールから逆算して必要なプロダクトを考える
- 互換性と柔軟性
- 時間的な制約がある場合にはコンサルタントを活用する
4-1.ゴールから逆算して必要なプロダクトを考える
例えばデータレイクを導入する目的が機械学習やAIによってモデルを構築し、需要予測や異常検知といった予測によってビジネス上の戦略に役立てることであるとします。すると、データレイクは単にデータウェアハウスにデータを供給するだけでなく、以下の条件を満たす必要があります。
- 分析者が探索的に見ることができ、その際にデータが破損する恐れがない
- 機械学習のライブラリが豊富なPythonやRといった機械学習の言語への拡張性がある
4-2.互換性と柔軟性
データレイクを選定する上では既存のデータベースやデータウェアハウスなどのツールとの互換性を把握するべきです。データベースと相性がよく、スムーズにデータの受け渡しができ、データウェアハウスへのデータの書き出しも問題なくできればストレスなく導入できます。例えばSnowflakeであればデータレイクの機能とデータウェアハウスの機能が両方あるので、1つのツール内でデータの保存を完結することができ、さらに接続できるデータベースやBIツールも豊富にあります。
次に、データ分析基盤の柔軟性とは、PoC(導入前検証)のように小さく始めることができ、なおかつビッグデータにも対応できることを指します。PoCをしたいのに初期導入コストが高すぎたり、ビッグデータを入れるとクエリの実行が極端に遅くなるようなデータ分析基盤はあまり優れているとは言えません。最新のクラウド型データレイクやデータウェアハウスであれば使った分の料金を払う仕組みになっているため、この問題を解決できます。
4-3.時間的な制約や社内にノウハウの蓄積がない場合にはコンサルタントを活用する
特に早く進めていきたい、今すぐにデータ分析基盤を導入したい場合には、コンサルタントを利用したほうがいいかもしれません。自社単体で進めると要件定義がうまく固められなかったり、必要なツールの選定に時間がかかったりするため、導入までに時間がかかってしまいます。
まとめ
今回はデータレイクとデータウェアハウスに関して比較し、特徴から導入まで詳細にご説明しました。データレイクで何ができるのかを把握したうえで導入に取り組み、効果的にビジネスに役立てていただければ幸いです。
データ分析基盤を構築する上では、以下を踏まえた上でコストやデータガバナンスなど様々な視点から必要な製品の選定、実際の導入を検討する必要があります。
- どんなデータを分析したいのか
- 何を実現したいのか/どんなサービスに活用したいのか
- どんなインサイトが得たいのか
弊社では単なる導入だけでなく、導入後のお悩みに向き合い、データマネジメントやデータガバナンスの観点から戦略立案を行う豊富な経験を有しております。既にデータ分析基盤を構築されている場合でもお気軽にご相談ください。


コメント