
データの活用が注目される中で、「データライフサイクル」という言葉を聞いたことはありませんか?
これは、データが生成されてから廃棄されるまでの一連のプロセスを指す言葉で、DXやデータガバナンスを進める上で避けては通れない概念です。
本記事では、「データライフサイクルとは何か?」から、「各フェーズの具体的な内容」「企業における活用方法」までを、わかりやすく整理して解説します。
目次
データライフサイクルとは?
データライフサイクル(Data Lifecycle)とは、データが誕生してから活用され、最終的に削除されるまでの流れを指します。
例えば、以下のような流れです。
データの生成
データの収集
保管・整理
活用(分析・可視化など)
社内外への共有
長期保管(アーカイブ)
削除・廃棄
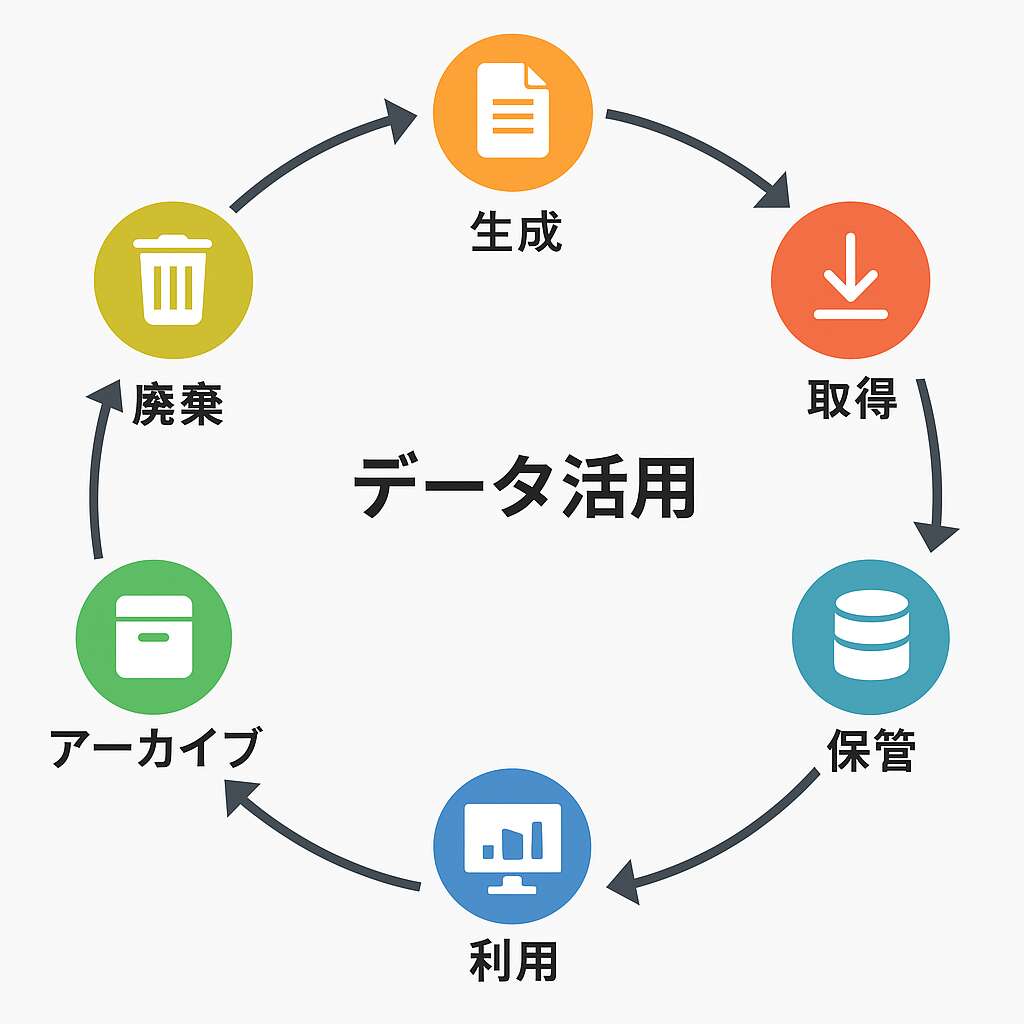
このサイクルを意識せずにデータを扱うと、情報漏洩・管理ミス・業務非効率につながるため、企業の情報資産管理において極めて重要な考え方です。
なぜデータライフサイクル管理が重要なのか?
現代企業においてデータは「資産」であり、「リスク」でもあります。
情報漏洩リスクの抑制(例:旧社員のデータが無制限に閲覧可能だった)
コンプライアンス遵守(例:GDPR違反での罰金リスク)
業務効率化(不要データ削減、再利用性向上)
DX推進におけるデータ基盤強化
“使えるデータを、使いたいときに、安全に使える状態で維持する”ことこそが、データライフサイクル管理の目的です。
データライフサイクルの7フェーズと実務での例
① 生成(Creation)
データは様々な場所で生成されます。
例:
IoTセンサーのログ
アンケート回答
Webフォーム入力
社内システムへの登録情報
生成された時点から、すでにデータのライフサイクルは始まっています。
② 収集・取得(Acquisition)
生成されたデータは、システム間連携や手動で集められます。
例:
ETLツールでデータを統合
CSVでアップロード
API連携による自動取得
「どこから」「誰が」「何の目的で」取得したのかの記録(メタデータ)を残すことが、後のトラブル回避に有効です。
こちらの記事には、データ収集について詳細を記載しています。
データ収集の重要性と技術的方法&よくある課題と対応策を解説
③ 保管・保存(Storage)
収集したデータは適切に保存する必要があります。
例:
RDB(リレーショナルデータベース)
クラウドストレージ(AWS S3など)
ExcelやGoogleスプレッドシート
保管時には「暗号化」「バックアップ」「アクセス権限の管理」など、情報セキュリティ面の対応も求められます。
④ 利用(Use / Processing)
データは活用してこそ価値を生みます。
例:
ダッシュボードでのKPIモニタリング
MA/BIツールでの顧客分析
AIによる予測分析
このフェーズでの最大のポイントは、「使える形で整理されていること」。保管までが終わっても、整備が不十分だと活用できません。
⑤ 共有(Sharing)
データは、社内外と連携して初めて大きな力を発揮します。
例:
他部署とのKPI共有
顧客向けレポート作成
パートナー企業との連携データ提供
このとき、誰が見ていいか/見てはいけないかの権限管理が極めて重要になります。
⑥ アーカイブ(Archive)
一定期間を過ぎたが、保管義務のあるデータはアーカイブされます。
例:
税務対応のため7年間保管
契約情報やログの保管
社内業務ルールに応じた保管期間の設定
検索性を確保したままコストを下げる工夫が求められます。
⑦ 廃棄(Deletion / Disposal)
ライフサイクルの最終段階。
削除は単なる消去ではなく、安全かつ復元不能な手法での完全削除が求められます。
特に個人情報や機密情報については、法律(個人情報保護法・GDPR等)に則った廃棄が義務です。
実務における課題と対策
データライフサイクルは、理屈としては理解しやすくても、実務で運用されていないケースが多く見られます。
以下の表は、各フェーズにおける「理想的な状態」と「現場でよくある課題」を比較したものです。
| フェーズ | 理想的な状態 | よくある課題 |
| 生成 | 目的に沿った構造でデータ設計されている | 無目的で項目が増え続ける |
| 収集 | 自動化+メタ情報も取得される | 手作業で属人化、記録も曖昧 |
| 保管 | セキュアかつ整理されたストレージ | ファイルが散乱・個人PC管理 |
| 利用 | 誰でも再現可能な分析環境 | 特定の人しか使えず属人化 |
| 共有 | 権限設定の上で円滑に連携 | 無断共有、情報漏洩リスク |
| アーカイブ | ルールに基づいた長期保存 | 「とりあえず全部残す」状態 |
| 廃棄 | 記録付きで安全に削除 | 期限切れデータも放置される |
データライフサイクル管理に必要な関係者
また、データライフサイクルを実際に運用・管理していくためには、「誰がどのフェーズに関わるのか?」を明確にする必要があります。データライフサイクルの各フェーズに関わる部門と担当者の一例(関係者マッピング)の大まかな枠組みは以下のようになることが多いです。
| フェーズ | 主な関係者(部門・職種) |
|---|---|
| 生成 | マーケ部門、営業、開発、業務部門 |
| 収集 | 情報システム部門、データエンジニア |
| 保管 | インフラ・セキュリティチーム |
| 利用 | 経営企画、マーケ、アナリスト、業務責任者 |
| 共有 | 情報システム、法務(データ共有方針のチェック) |
| アーカイブ | 情報システム、総務、経理 |
| 廃棄 | 情シス、法務(法定保存期間の考慮) |
まとめ:まずは「自社のどこにデータがあるか」を可視化しよう
データライフサイクルは、IT部門だけでなく、ビジネス部門・経営層も理解すべき「データ活用の土台」です。
「今あるデータは、どこで生まれて、誰が使って、いつ消されるのか?」
これを言語化できることが、次のDXステップのスタートラインになります。
以下のデータガバナンスの記事もご参考にされてください。
データガバナンスとはデータマネジメントを監督すること




