
データ分析・可視化のクオリティを向上させるための方法として、データクレンジングがあります。本記事を読み終えれば、データクレンジングの概要を理解し、自社データにどんなデータクレンジング手法が有効なのか理解いただけるでしょう!
目次
1. データクレンジングとは
1.1 データクレンジングは不適切なデータを置換・修正・削除するプロセス
データクレンジングはデータ分析・可視化を行う前段階で、csvファイルやデータベース内の不適切なデータを修正・削除・置換するプロセスのことであると定義されます。
不適切なデータというのは、データ自身が間違っている場合(重複登録されている、半角全角が混在しているなど)もありますし、データ自身は正しいが分析に適した形式になっていない(データ量が多すぎる、文字型が分析に適さない)という場合にもあります。
1.2 データクレンジングの目的はデータ活用の効率化・高度化
データクレンジングは、データ活用の効率化・高度化を目的として実施されます。
データクレンジングされていない重複があるデータでダッシュボードを作ることは可能です。しかし、実際にユーザーが使用する際に、一度エクセルにダウンロードし手動で重複を削除したり、不備を編集したりといった作業が必要になります。データクレンジングによって整備されたデータを使用すれば、ユーザーは手動でのデータ整形をせず、効率的にダッシュボードを利用することができます。
また、データクレンジングはデータ活用の高度化にも寄与します。機械学習で、生データをそのまま使用してしまうとハズレ値に大きく影響されてしまいます。データクレンジングで適切なデータのみに整備し、機械学習処理を行うことでより高度な分析を行うことができるでしょう。
1.3 データクレンジングは即効性とコストパフォーマンスに優れている
データクレンジングでデータを加工することのメリットは、即効性とコストパフォーマンスにあるといえます。
データクレンジング以外にも、システム改修を行い入力規則を設けたり、ユーザーへ正しくデータを入力するように教育することでデータ品質を向上させることはできます。しかし、いずれの方法も実施からその効果が現れるまでには時間がかかりますし、作業者の工数も含めた費用はそれなりにかかります。
データクレンジングは、後述するようにエクセルでも行うことができ、実施すればすぐに結果がデータに反映されるのですぐに品質の良いデータで分析に取り組むことができます。
データマネジメントを推進するデータビズラボの研修資料をダウンロードする
2. データクレンジングの代表的な手法
手法名 | 概要/例 |
重複データ除去 | 重複している同一内容のレコードを削除する |
データの正規化 | データの表記形式を揃える |
欠損値の処理 | 欠損値を含むレコードを削除したり、平均値・代表値で補完する |
データ型変換 | 分析処理に向いた型にデータ型を変更する |
単位変換 | 分析処理に向いた型にデータの単位を変更する |
異常値除去 | 外れ値などデータの基本統計量に大きな影響を及ぼすレコードを削除する |
フィルタリング | 分析処理を効率化するために、必要な範囲でデータを絞り込む |
エンコーディング | 質的データを量的データに変換する |
データトリミング | データの先頭や末尾に存在する不用意なスペースを削除する |
名寄せ | 旧漢字と新漢字など、同一の物や人物名を異なる表記で表現された複数のデータを一つの名称で統一する |
Tableau Prepのようなデータプレパレーションツールで行えることは全てデータクレンジングと言って良いくらい、データクレンジングにはデータ分析を行う上でのデータ準備プロセスのあらゆることが含まれています。よって、上記はデータクレンジング手法のほんの一部です。しかし、上記はExcelなどで容易に実施でき、データ可視化・分析に与える影響も大きいです。
データクレンジングに取り組みたいが、何をすれば良いのかわからないという方はぜひ、上記手法からトライしてみることをお勧めします。
3. 代表的なデータクレンジングツール
データクレンジングを行うためのツールは多くあります・ここでは代表的かつ多くの方に馴染みのありそうなものを3つ紹介します。
Microsoft Excel
この記事を読んでいる方であれば触ったことはないであろう、表計算ソフトです。下記で紹介するツールに比べるとアナログチックな操作が必要ですが、大文字から小文字への変換や不要スペース削除などは容易に行えます。
メリット:すぐに使用できる環境であることが多く、操作も容易である。
デメリット:データ量によっては動作が遅くなる。データクレンジングプロセスの自動化をすることは難しい。
Pandas(Pythonライブラリ)
Pythonでデータを扱うことに慣れている方であれば、Pandasを使用してデータクレンジングを行うこともできます。
メリット:PCとネット環境があれば無料でできる。Excelで処理できないサイズのデータも処理できる場合がある。将来的に処理プロセスを自動化する際の難易度は低い。
デメリット:Pythonのスキルが必要。

AWS Glue
AWS GlueはAWS内のETLサービスです。クラウド上で動作するため、あらゆる量のデータに適用できます。
メリット:膨大なデータに対しても処理を実行できる。さまざまなツールからのデータ統合コネクタが用意されており、データ抽出・加工・ロード処理を自動化できる。
デメリット:費用がかかる。クラウドで動作するため、秘匿性の高いデータを扱う際はセキュリティ面の設定も必要

4. データクレンジングの進め方
本章では実際の業務でどのようにデータクレンジングに取り組むべきかを説明します。前章で、データクレンジングには様々な手法があることを説明しました。しかし、取得したデータに対して全てを適用することは非効率です。
実際の業務では、データ活用のゴールから逆算して、必要なデータクレンジングを行うことをお勧めします。
STEP1:データ活用の目的を定義する
いきなり生データをみて課題を探すのではなく、最初はデータ分析の目的とユースケースを定義しましょう。その分析結果を誰がどのように業務に活かすのかを定義しましょう。
完璧なデータ品質を目指すあまり、不要な部分までデータクレンジングを行うことは、無駄に工数がかかってしまうだけで実際の業務に寄与しません。必要最小限の費用・工数で、データ分析・可視化を行うために、これらの指針を定義しましょう。
STEP2:目的を達成するために必要なデータ品質を定義する
データ活用の目的・ユースケースを定義した後は、その分析に必要なデータの状態を定義しましょう。具体的にはカラム名・文字型と言ったテーブル定義とそのデータに適用する計算式を定義出来れば良いでしょう。
これらを行うことで、分析にどんなデータが必要か・そのデータはどれくらいの粒度であるべきかを整理することができます。
STEP3:現状のデータを確認し、課題を特定する
ここまでできれば、生データを確認し、分析に必要なカラムは揃っているか、データの粒度は分析に適しているかを確認しましょう。
事前に必要なデータの状態を定義しておくことで、必要最小限の工数で生データの課題を特定できるでしょう。また、課題を特定するだけでなく、その課題が分析にとってどれくらい重要かの観点で優先度を定義しましょう。課題の中には、データクレンジングの手法だけでは対策できないものもあるかもしれません。そう言ったものは、データ入力担当者が正確に入力するための教育のようなデータマネジメント活動や、システム改修のアイデアとして今後の検討課題としましょう。
STEP4:優先順位を決めて修正する
ここまでできれば、実際のデータクレンジング手法の出番です。
特定した課題に対して、データクレンジングを実施しましょう。Saasなどのツールもありますが、まずはExcelやPythonのPandasを用いてアナログに修正を進めることをお勧めします。ノーコードのETLツールやデータプレパレーションツールは便利な反面、狙い通りにデータ加工を行えているかを確認することが難しく、ミスがあった際の原因解明も難解です。まずはアナログにデータ加工を行い、加工手順の一つ一つを検証しましょう。データの全レコードをExcelなどで処理することが難しい場合は、データを適当な行でサンプリングし、検証しても良いと思います。
その後、そのクレンジング手法が適切であればETLツールを用いたパイプラインを構築することでデータクレンジング作業を自動化しましょう。
5. 実際に私が行ったデータクレンジング2例
例1:放送局視聴率データの時間変換
放送局の案件で下記に示すような番組ごとの視聴率が示された視聴率データがありました。
| 番組名 | 放送日 | 放送開始時間 | 視聴率[%] |
| AAA | 2022/3/1 | 8:56 | 9 |
| BBB | 2022/3/1 | 9:45 | 6 |
| CCC | 2022/3/1 | 11:00 | 8 |
クライアントはこのデータから0:00-23:00までの1時間ごとの視聴率データを作成し、多くの社員が直感的に視聴率の時系列推移を理解し、視聴率への馴染みを深めたいと考えていました。しかし、上記のデータでは番組開始時刻しかデータが存在せず、0:00, 1:00・・といった1時間単位の時系列推移を記載することができませんでした。
そこで、我々は放送開始時間が1分単位となる以下のテーブル手動で作成し、ダッシュボードを作成しました。その後、クライアントのエンジニアがPythonでこのデータクレンジグプロセスを記述し、ETLプロセスに組み込むことで自動化しました。
| 番組名 | 放送日 | 放送開始時間 | 放送時間 | 視聴率 |
| AAA | 2022/3/1 | 8:56 | 8:56 | 9 |
| AAA | 2022/3/1 | 8:56 | 8:57 | 9 |
| AAA | 2022/3/1 | 8:56 | 8:58 | 9 |
| AAA | 2022/3/1 | 8:56 | 8:59 | 9 |
| AAA | 2022/3/1 | 8:56 | 9:00 | 9 |
| AAA | 2022/3/1 | 8:56 | 9:01 | 9 |
| AAA | 2022/3/1 | 8:56 | ・ | 9 |
| AAA | 2022/3/1 | 8:56 | ・ | 9 |
| AAA | 2022/3/1 | 8:56 | 9:44 | 9 |
| BBB | 2022/3/1 | 9:45 | 9:45 | 6 |
| BBB | 2022/3/1 | 9:45 | 9:46 | 6 |
| BBB | 2022/3/1 | 9:45 | ・ | 6 |
| BBB | 2022/3/1 | 9:45 | ・ | 6 |
| BBB | 2022/3/1 | 9:45 | 10:58 | 6 |
| BBB | 2022/3/1 | 9:45 | 10:59 | 6 |
| CCC | 2022/3/1 | 11:00 | 11:00 | 8 |
| CCC | 2022/3/1 | 11:00 | 11:01 | 8 |
| CCC | 2022/3/1 | 11:00 | 11:02 | 8 |
例2:インデックス形式DBの加工
建設会社にて、工事履歴システムをBIツールにて可視化し、社員の経験工事検索を容易にしたいという要望がありました。データソースは工事履歴システムのデータベースでしたが、いわゆるインデックス型となっており、そのままBIツールに読ませて可視化をすることが難しい状況でした。
そこで、カラム名がそのまま列のデータの名称となるようなデータへSQLを用いて加工しました。
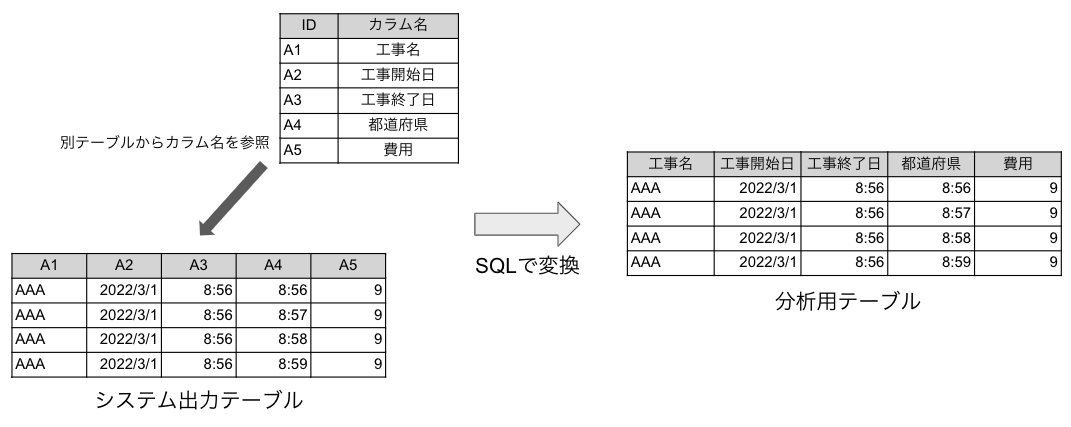
(上記2例とも説明のためにデータ形式を簡素化していますが、実際にはもっと複雑で大規模なデータを使用していました。)
6. データクレンジングはデータ品質改善の万能薬ではない
これまで、データクレンジングの重要性・有効性を述べてきましたが、データクレンジングはデータ分析・可視化のクオリティ向上における対症療法的な側面があり、全てのデータ品質課題に対応できるわけではありません。
例えば、データの虫食いでは数値データでは平均値・代表値で補完する方法もありますが、住所や人名といったデータはデータクレンジングで補完することは難しいでしょう。このような場合には、データの入力担当者にきちんとデータを入力するよう教育したり、システム改修によって入力を必須としたりと言った方法をとる必要があります。
しかし、これらの手法はこれまで蓄積された過去のデータに対して行うことは難しく、現状のデータ活用を高度化することには寄与しないでしょう。対症療法ではあるものの、既存のデータの価値を高める上でデータクレンジングは非常に重要な役割を担っているのです。
7. まとめ
データクレンジングによるデータ分析・可視化のクオリティ向上の重要性を述べてきました。データクレンジングはビジネスに有効なデータ活用を行う上で非常に重要なプロセスです。Excelでも実施可能なので、ぜひ取り組んでみてはいかがでしょうか。
データの管理・活用でお困りの場合はデータビズラボへお問い合わせください。
状況やニーズに合わせた様々なサポートをご提供いたします。




